
住所表記ゆれ、システム不一致の壁
夜遅く、静まり返ったオフィスでExcelと格闘していた時のことです。手元には住民票のコピーがありました。画面のデータと見比べながら、思わずため息が漏れます。作業が最後に止まってしまった原因は、たった一つの項目、そう「住所」でした。
ディスプレイには「東京都港区芝公園4-2-8」と表示されています。一方で、紙の住民票には「東京都港区芝公園四丁目2番8号」とあります。わずかに異なる文字列ですが、人間の目には同じ場所にしか見えません。しかし、システムは非情にも「不一致」というエラーを出し続けていました。胃の奥がずしりと重くなるのを感じます。この単純に見える差異が、何百、何千というデータで発生していることを想像すると、血の気が引いていくのが分かりました。
まず、この問題の根源は、日本語の住所表記が持つあまりにも豊かな「表記ゆれ」にあると考えています。
日本特有の表記ゆれ、データ管理の落とし穴
例えば、ハイフンでつなぐ「1-2-3」という表記。あるいは、それを丁寧に書いた「一丁目2番3号」。どちらも日常的に使われる表現ですが、コンピュータはこれらを全く異なる文字列として認識します。人間が文脈から補完している「同じ意味」という情報を、機械は理解できないのです。
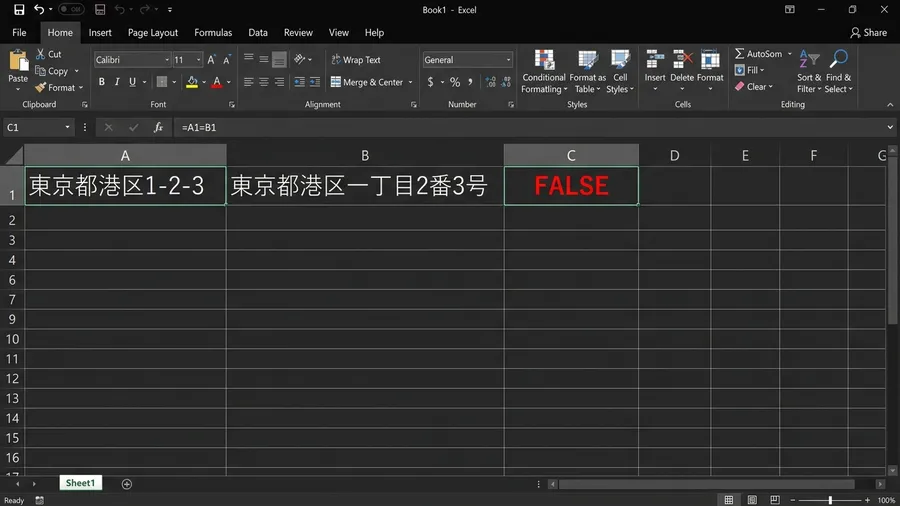
他にも、全角と半角の数字やカタカナの混在、アラビア数字と漢数字の使い分け、「ヶ」と「ケ」のような異体字など、そのバリエーションは無限に思えるほど存在します。これらは全て、データの突合作業において致命的な障害となります。
以前、顧客リストの名寄せ作業を担当した際、この表記ゆれを見抜けなかったことがあります。結果として同一人物にキャンペーンのダイレクトメールを2通送付してしまい、「個人情報の管理はどうなっているんだ」という厳しいお叱りを受ける羽目になりました。電話口で平謝りしながら、冷や汗が背中を伝ったのを今でも鮮明に覚えています。
単なる入力ミスではありません。これは、日本の住所が内包する構造的な問題なのです。そして、この問題はさらに根深い、もう一つの罠へとつながっています。
住所の落とし穴:住居表示と地番
表記ゆれの問題をなんとか乗り越えようと情報を集め始めると、さらに巨大な壁に突き当たることになります。「住民票に記載されている住所が絶対的な正解だろう」という素朴な信頼は、あっけなく崩れ去るのです。
実は、日本の住所体系には大きく分けて2つの種類が存在します。一つは私たちが普段郵便物などで目にする「住居表示」、もう一つは土地の権利を管理するための「地番」です。
住居表示は街を分かりやすく区画し、建物を順番にナンバリングしていく方式で、「〇丁目〇番〇号」という形式が一般的であり、主に市町村が定めています。一方で地番は、法務局が土地一筆ごとに割り振る管理番号であり、「〇〇町字△△ 1234番地」のように、より古い地名が使われることも少なくありません。
重要なのは、この二つが必ずしも一致しないという事実です。住民票に記載されるのは原則として「住居表示」ですが、住居表示がまだ実施されていない地域では、今でも「地番」が住所として使われています。
システムを阻む住所データの構造的な罠
全国の自治体における住居表示の実施率は約6割程度です。つまり、日本全国どこでも同じルールで住所が管理されているわけではないのです。この事実を知らないまま、「住民票のデータを正として、ユーザー入力データをクレンジングしよう」と意気込むと、かえってデータを混乱させる危険すらあります。
顧客がフォームに入力した住所が、普段使いの「住居表示」なのか、あるいは不動産の契約書から転記した「地番」なのか。どちらもその人にとっては「正しい住所」であり、嘘ではありません。しかし、システムが求める唯一無二の「正解」とは乖離していきます。この構造的な罠が、データ担当者の行く手を阻むのです。
住所データ管理の難題、システムと現場の板挟み
住所の問題と向き合っていると、ふと根本的な疑問が湧いてきました。「そもそも、このシステムで管理したい正解って何なんだろう?」と。
システム開発の観点から見れば、答えは「きれいな文字列」です。データは正規化され、一意性が保たれていなければなりません。重複や表記ゆれは、データ分析や連携の際に問題を引き起こす要因となります。そのため開発者は、入力フォームに厳しいバリデーションをかけ、「『1-2』のような入力は許可しません。『〇丁目〇番〇号』の形式で正しく入力してください」といった要求を出すことになります。
しかし、業務の現場から見れば、それは少しハードルが高い要求に聞こえるかもしれません。顧客に煩わしい入力を強制して離脱されては本末転倒です。業務担当者が求めているのは、あくまで「その人に書類が届く」「本人確認が取れる」という目的の達成であり、データベースの美しさではないのです。
住所データ正規化のジレンマ
以前、開発チームと現場の業務担当者の間で板挟みになったことがあります。開発からは「住所データの正規化は必須です」と強く言われ、現場からは「お客様にそんな負担はかけられない」と突き返される。会議室の重い空気の中で、どちらの言い分も理解できるだけに、胃がキリキリと痛んだことを覚えています。システムの正しさとビジネスの現実。その狭間で、プロジェクトが完全に停滞してしまったのです。
システムのための業務であってはなりません。しかし、汚れたデータを放置し続ければ、いずれシステムは信頼性を失い、業務そのものが成り立たなくなります。このジレンマこそが、住所問題の最も厄介な側面だと感じています。
Python・業務自動化を動画でじっくり学ぶなら
Pythonでの業務自動化を基礎から動画で学びたい方には、オンライン学習サイト「Udemy」が選択肢です。自分も書籍だけでは理解できなかった部分を、動画講座で手を動かしながら覚えました。セールのタイミングなら手頃な価格で始められます。
住所突合の現実解、8割効率化
理想的な解決策が存在しない以上、現実的な落とし所を見つけるしかありません。完全な自動化という夢は一旦脇に置き、機械と人間のハイブリッドでこの問題に立ち向かうという、極めて泥臭いアプローチを採用することにしました。
まず、機械にできることは徹底的に機械に任せます。Pythonのようなプログラミング言語を使い、単純なルールベースの正規化処理をスクリプト化しました。具体的には、全角英数字や記号を半角に統一する、漢数字をアラビア数字に変換するといった処理です。これだけでも、かなりの表記ゆれを吸収できます。
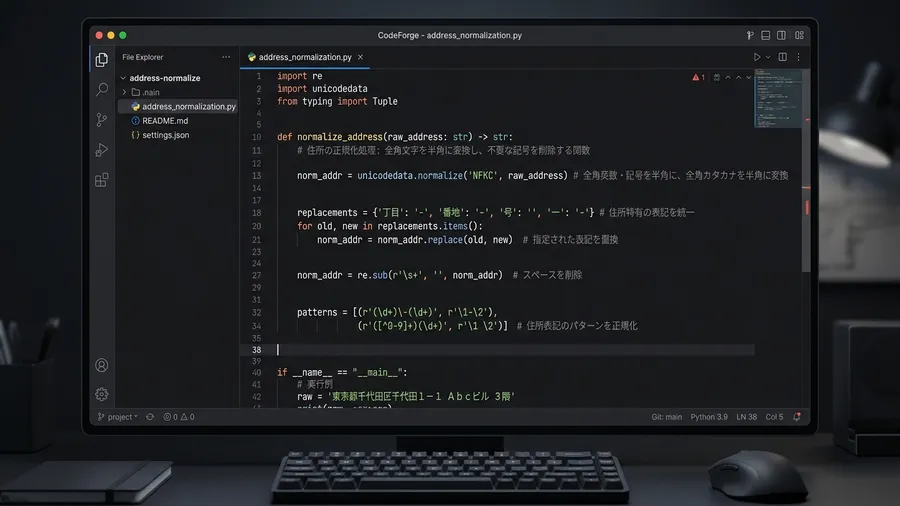
次に、もう少し高度な変換ルールを適用します。「丁目」「番地」「号」といった文字列をハイフンに置換するパターンとその逆のパターンを用意し、両方の形式で住所文字列を生成します。この処理を経たデータ同士で突合を行うことで、マッチングの精度をさらに向上させました。
住所突合の効率化、人と機械の融合
しかし、これでも全てのパターンを網羅することは不可能です。どうしても機械的な判断が難しいケースは残ります。「〇〇ビル 301」と「〇〇ビルディング 3F-1」のような、人間の知識がなければ同一と判断できないものたちです。
最終的に、これらの「機械が判断を保留したデータ」だけをリストアップし、そこから先は人間が目視で確認するという運用フローを構築しました。そして、「どちらを正とするか」という問いに対しては、「住民票の写しなど、提出された公的書類の表記を正とし、ユーザー入力データはそれに追随する形で更新する」という明確な社内ルールを定めています。
この仕組みを導入した結果、完全な自動化は実現できなかったものの、住所突合の手作業確認件数を80%以上削減するという大幅な効率化に成功しました。これは、技術の限界を認め、人間の判断という「コスト」を本当に必要な箇所にだけ集中投下するという現実的な選択の結果だったのです。
AI住所正規化:その能力と人の判断
近年、生成AIの進化は目覚ましいものがあります。そこで、この厄介な住所問題についてAIに相談相手になってもらうことを試みました。「日本の住所の多様な表記ゆれを吸収できる最強の正規化ロジックを考えてほしい」と尋ねてみたのです。
AIの回答は驚くほど優秀でした。考えられる表記ゆれのパターンを網羅的にリストアップし、それを処理するためのPythonコードまで即座に生成してくれました。その内容は、我々が数週間かけて議論し、試行錯誤の末にたどり着いたロジックと非常によく似ていました。技術的な課題解決において、AIが強力なパートナーになることは間違いありません。
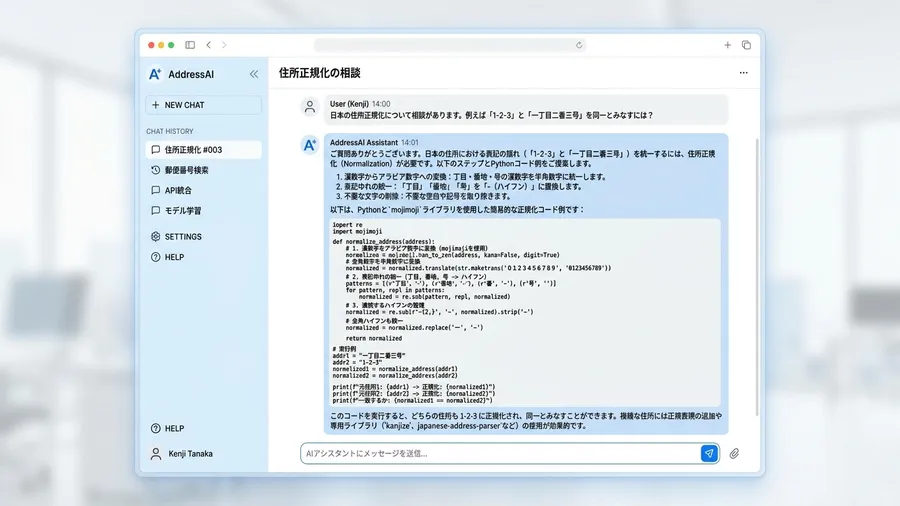
しかし、AIとの対話を通じて、同時に技術だけでは越えられない壁の存在もまた明確に浮かび上がってきました。AIは完璧な正規化ルールを提案してくれますが、「で、結局どちらの表記が本当に正しいのですか?」という最終的な問いには答えられないのです。
AIの限界と住所正規化:システムと現実のギャップ
例えば、「京都府京都市中京区上る下る…」といった、地域固有の複雑な住所表記や、同じ建物内でも登記上は別々の地番にまたがっているケースなどは、現地調査や公的な資料といった「事実」と照らし合わせなければ判断できません。AIはウェブ上の膨大なテキストデータから「最も確からしいパターン」を学習しているに過ぎず、個別の不動産が持つ物理的な現実にアクセスすることはできないのです。
以前、AIが生成した正規化ロジックをテスト的に導入した際、ある特定の地域の住所データが軒並み文字化けするという事態が発生しました。AIは一般的なパターンに最適化されすぎており、その地域の特殊な番地体系を「ノイズ」と判断して誤った変換をかけてしまったのです。結局、その地域のルールを知る人間の手で修正するしかありませんでした。技術への過信が招いた失敗です。
システムと現実の溝を埋める住所修正
将来、デジタル庁が推進する「アドレス・ベース・レジストリ」のように、全ての住所に一意のIDが割り振られるようになれば、この問題は根本的に解決するかもしれません。しかし、その未来が訪れるまでは、我々は目の前の不完全なデータと向き合い続ける必要があります。AIは強力な武器ですが、最後の引き金を引くのは常にドメイン知識を持った人間なのです。
住所の正規化という一見地味な作業は、単なる文字列処理の問題ではありませんでした。それは、日本の行政の歴史、人々の生活習慣、およびシステムと現実世界の間に横たわる深い溝そのものと向き合う仕事だったのです。
技術は万能ではありません。ExcelやVBA、Pythonを駆使して業務を効率化しようとするとき、我々は必ずこの「技術では解決できない領域」に突き当たります。大切なのは、そこで思考を停止しないことです。どこまでを機械に任せ、どこからを人間の判断領域として残すのか。その境界線を冷静に見極めることが大切です。
住所修正:現実とシステム、奥深き橋渡し
住所の修正は地味な作業ですが、やってみると実は奥が深いものです。システムと現実のギャップを埋めるこの仕事、意外とバカにできないなと感じながら、今日もExcelを叩いています。あなたの目の前にある、住民票と入力データの「微妙な違い」。その差を埋めるための試行錯誤は、決して無駄ではありません。それは、無機質なシステムに現実世界の複雑さを教え込み、両者の間に信頼できる橋を架けるという、非常に価値のある仕事なのです。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
関連書籍
業務効率化関連書籍を、手元で見返せる形にしておきたい場合
業務効率化は、いきなり大きく変えるより、手元の作業を1つずつ減らすほうが続けやすいです。考え方を見返せる本があると、次の一手を選びやすくなります。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。