
PythonでのCSV文字化け、文字コードの洗礼
朝一番のコーヒーを一口飲みました。意気揚々とパソコンに向かうことにしたのです。昨夜は遅くまでかかってしまいました。書き上げたPythonのプログラムを、ようやく動かす瞬間がやってきたのです。目的は非常に単純なものでした。基幹システムから出力された、数万行の売上データを読み込みます。CSV形式で読み込みを行い、集計作業を自動化することを目指していました。これさえ終われば、作業は一気に楽になります。今まで丸一日かかっていたエクセル作業が、数秒で完了するはずでした。
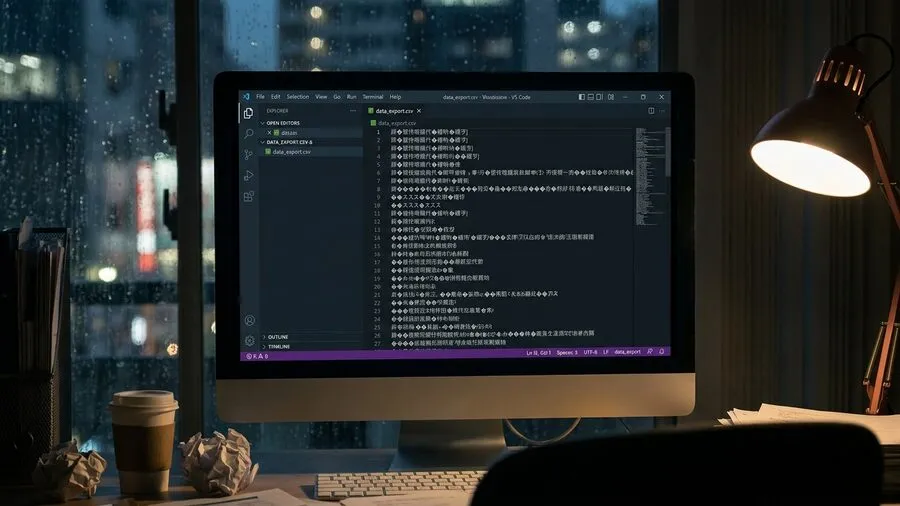
しかし、画面に表示されたのは違いました。期待していた整然たる数字の列ではなかったのです。そこにあったのは「繧ゅ§縺ー縺代」という文字でした。まるで呪詛のような、記号の洪水が広がっていたのです。一瞬、自分の視力が急激に落ちたのかと疑いました。慌てて眼鏡を拭き直したことを覚えています。ですが何度見ても、画面上の文字は意味をなしていません。顧客名の列も商品名の列も、すべてが崩壊していました。背筋に冷たいものが走ります。指先が少し震え、マウスを持つ手には、じっとりと汗が滲んでいました。
Python初挑戦、文字コードの洗礼
まず、初めてPythonでCSVを読み込んだ時のことです。ターミナルの一面が、読めない記号で埋め尽くされました。自分の書いたコードが原因かもしれません。基幹システムのデータを破壊したのではないかと、本気で焦りました。心臓の鼓動が耳元まで響くほど、速くなっていました。慌ててエクセルを使い、元のファイルを開き直します。中身が無事であることを確認して、ようやく椅子に深く背を預けました。しかし、その時点ですでに1時間が経過していたのです。
原因については、全く見当もつきませんでした。コードそのものには、エラーが出ていないのです。プログラムは正常に終了したと告げています。それなのに、出力された結果はゴミの山に等しい状態でした。事務職の身として、データが壊れることは非常に恐ろしいことです。もしこのまま上司に報告すれば、厳しく言われるかもしれません。「これだから素人が手を出すと困るんだ」と、一蹴される不安が頭をよぎりました。そのせいで、胃のあたりが重く沈み込んでいきました。
見えないルール、文字コードの壁
世の中には、日本語を表現するためのルールがあります。それが文字コードであり、数十種類以上も存在しています。その事実すら、当時の私は知りませんでした。私たちは普段、エクセルを使っています。その時に「文字コード」という概念を意識することはありません。ただファイルを開けば、そこに文字があります。それが当たり前だと思い込んでいたのです。
Python CSV 文字化けの沼
次に、必死に解決策を求めて検索を行いました。検索窓に「Python CSV 文字化け」と打ち込みます。返ってきた検索結果には、知らない言葉が並んでいました。「エンコーディングを正しく指定しましょう」という助言です。「Shift-JISかUTF-8か確認してください」とも書かれています。エンコーディング。それは今まで生きてきた中で、一度も必要としなかった単語でした。エンジニアの方にとっては常識なのでしょう。しかし、総務や経理の人間からすれば、呪文と大差ありませんでした。

解説記事を読み進めるほど、頭の中が霧に包まれていきました。Unicode、CP932、BOM付き、デコードエラー。専門用語の波が次々と押し寄せ、理解を拒んできます。なぜただのテキストファイルを読み込むだけで、これほど苦労するのでしょうか。自動化して楽になりたかっただけなのです。しかし、皮肉なことに手作業の時よりも時間を費やしました。何もできないまま、画面の前で多くの時間を浪費してしまったのです。
UnicodeDecodeErrorと格闘した午前中
ネットで見つけた断片的なコードを試しました。「これを試せ」という記述を、片っ端からコピペしていきます。しかし、状況は悪化する一方でした。ある時は「UnicodeDecodeError」という文字が出ます。赤い文字のエラーメッセージが、コンソールを埋め尽くしました。またある時は、エラーすら出ません。しかし、ファイルの中身が空になってしまいました。時計の針は11時を回りました。周囲の同僚たちが、ランチの相談を始めている声が聞こえます。自分だけが取り残されたような、孤独感と無力感に苛まれました。
UnicodeDecodeErrorと3時間の格闘
一方で、特に混乱を招いたのが特定のエラーでした。「UnicodeDecodeError」というエラーメッセージです。’utf-8′ codec can’t decode byte 0x82。この機械的な宣告は、拒絶を意味していました。私の書いたコードが、ファイルの門前で追い返されたのです。何が0x82なのか、なぜ門前払いされるのかが分かりません。理由が全く分からない状態でした。このエラーメッセージをAIに投げれば、何か答えてくれるのかもしれません。しかし、当時は何を質問すればいいのかさえ、言語化できない状態でした。
結局、午前中の3時間以上が過ぎていきました。検索とコピペ、そして落胆の繰り返しで終わったのです。エクセルで開けば、中身は普通に見えます。しかし、Pythonからはその中身が見えません。この断絶が、プログラミングという高い壁に感じられました。それは私にとって、非常に大きな象徴のように思えたものです。
cp932こそ、日本オフィス環境の守護神
午後になり、ある個人ブログの記事に目が止まりました。諦め半分で探していた時に、見つけた記事です。「WindowsのExcelで作ったCSVなら、とりあえずcp932を指定してみろ」。そこには、乱暴ですが力強いアドバイスが書かれていました。藁にもすがる思いで、コードを書き換えます。pandasの読み込み部分を修正することにしました。pandas.read_csv(‘file.csv’, encoding=’cp932′)。この短い記述を追加して、祈るように実行ボタンを押しました。
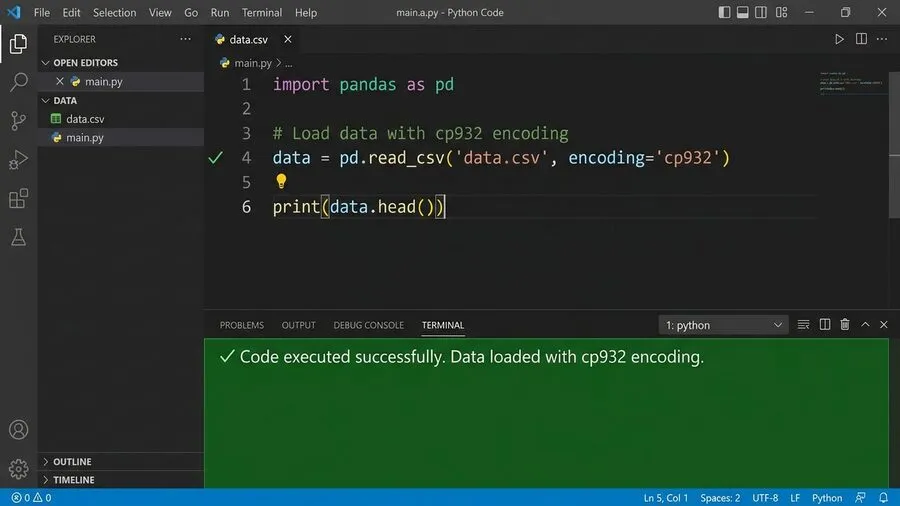
一瞬の静寂の後、ターミナルに変化が起きました。そこには、美しい日本語が表示されていたのです。顧客名、商品名、そして売上金額です。それらは本来あるべき姿で、整然とそこに存在していました。午前中のあの絶望が、まるで嘘のようです。データは完璧に読み込まれていました。わずか数文字の追加、たったそれだけの「おまじない」でした。それが、カオスだった画面を秩序ある世界へと引き戻してくれたのです。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
日本語表示の救世主「cp932
画面に正しく日本語が表示された時のことです。思わず「よしっ」と、小さく声が出てしまいました。向かいの席に座る同僚が、不審そうな顔でこちらを見ます。しかし、そんなことは全く気になりませんでした。何時間も悩んでいたことが、たった1行で解決したのです。わずか数秒の修正で解決した事実に、安堵しました。それと同時に、少しばかりの悔しさもこみ上げてきます。しかし、その時ようやく実感が持てました。「Pythonで仕事が進む」という確かな感覚を得られたのです。
この「cp932」という文字列について知りました。これは日本のオフィス環境における、守護神のような存在です。MicrosoftがShift-JISを拡張して作り上げたものです。日本独自の文字コード体系であるといいます。Excelという王者が支配するこの国では重要です。デファクトスタンダードとなっている存在なのだと学びました。
機種依存文字とcp932の役割
しかし、なぜ「shift_jis」ではないのでしょうか。なぜ「cp932」を指定する必要があるのかを考えました。その理由は、表現できる文字の範囲にあります。Shift-JISだけでは、「①」や「㈱」などの文字を扱えません。こうした機種依存文字を、cp932はカバーしているのです。もし「shift_jis」と指定していたらどうでしょう。これらの文字が含まれる場所で、またエラーが出ていたはずです。先人の知恵に従い、あえてcp932を選びました。そのことが、私をさらなる泥沼から救ってくれたのです。
ExcelとShift-JIS、文字化けの根源
解決した喜びが落ち着くと、一つの疑問が浮かびました。なぜ、こんな面倒なことが起きるのでしょうか。最初から世界中の文字を扱える、共通のルールを使えばいいはずです。しかし、そこには理由がありました。WindowsとExcelが歩んできた、長い歴史の中に隠されていたのです。
今の主流は、間違いなく「UTF-8」という文字コードです。これは世界中のあらゆる文字を、一つの体系で扱えます。Webの世界も、Pythonの内部処理も同様です。基本的には、このUTF-8が基準になっています。しかし、私たちのデスクトップにはExcelが君臨しています。Excelは互換性のために、今もShift-JISを使います。正確には、CP932を標準として使い続けているのです。Excelはデフォルトで、CSVをCP932で保存します。これが、日本で文字化けが起き続ける根本的な原因でした。
PythonでExcel文字化け解消術
Pythonは、UTF-8の世界に住んでいます。一方で、ExcelはShift-JISの世界に住んでいます。PythonがExcelのファイルを読み込もうとする時は大変です。言葉が通じない異邦人のような状態になってしまいます。これが、文字化けの正体なのです。翻訳者である「encoding=’cp932’」を省略してはいけません。指定を忘れると、Pythonは勘違いをします。「自分の国の言葉(UTF-8)だろう」と思い込むのです。その結果、意味不明な記号の羅列を吐き出すことになります。
文字コードの闇とシステムの壁
最近のExcelには、便利な形式があることを知りました。「CSV UTF-8」という保存形式です。試しにそちらで保存してみたところ、成功しました。確かに、Pythonでそのまま読み込めるようになったのです。しかし、今度はそのファイルを別の場所で使おうとしました。古い基幹システムにインポートしようとした際のことです。システム側で文字化けが発生してしまいました。情報システム部から連絡を受け、対応することになります。一方を立てれば一方が立たず、文字コードの闇を痛感しました。
BOM対策:Excel文字化け回避のutf-8-sig
さらに厄介なのが「BOM」という存在についてです。これはByte Order Markの略称となります。ファイルの先頭にくっついている、目に見えないサインです。「これはUTF-8ですよ」と教えてくれる目印のようなものです。ExcelはこのBOMの有無をチェックしています。それによって、UTF-8のCSVを正しく開けるかが決まります。もしBOMなしのUTF-8ファイルをExcelで開くとどうなるでしょう。今度はExcel側で、文字化けが起きてしまうのです。
この混沌とした状況に対応する方法があります。Pythonには「utf-8-sig」という指定が用意されているのです。コードの中に「encoding=’utf-8-sig’」と書きます。そうすれば、BOMがあっても適切に処理をしてくれます。cp932でダメなら、次はutf-8-sigを試しましょう。この二段構えを覚えたことは、大きな進歩でした。事務職としてのPythonスキルは、格段に向上したと言えます。
文字化けの壁、プロへの成長
一度コツを掴んでしまえば、もう怖くありません。あんなに恐ろしかった文字化けも、怖くないのです。それは単なる「設定ミス」に過ぎないからです。今では、文字コードを自動で推測する方法も知っています。
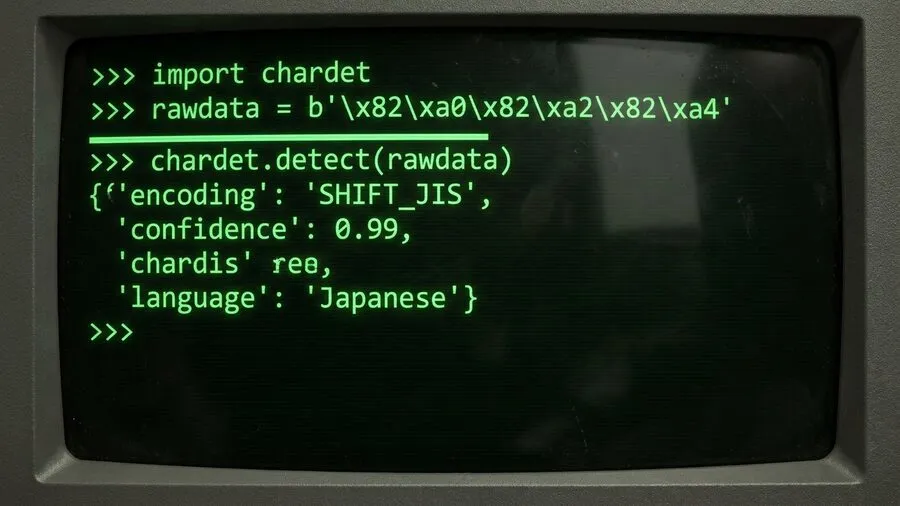
「import chardet」というライブラリを使います。これを使えば、人間が悩む必要はもうありません。プログラムが、ファイルのデータを一部読み取ります。そして、「これは99%の確率でShift-JISです」と判定します。このようにして、機械が文字コードを教えてくれるのです。
初心者にとって、最初の挫折ポイントはどこでしょうか。それはコードの書き方そのものよりも、環境かもしれません。こうした「環境のギャップ」であることが多いように思います。特に私たちは、エクセルという便利なツールに囲まれています。特殊な環境で仕事をしている私たちにとって、Pythonは異国です。Pythonの世界は、まさに異国そのものであると感じました。
異国のルールを学ぶ醍醐味
しかし、その異国のルールを理解していくことが大切です。一つずつ理解する過程こそが、業務自動化の醍醐味です。文字化けに苦しみ、壁に阻まれたあの日を思い出します。あの経験があったからこそ、今があります。私は確かに一歩、エンジニアの視点に近づいたのだと感じました。その感覚は、今でも私の中に大切な経験として残っています。
文字化け、私の成長点
次に「文字化けしています」という報告を聞いた時のことです。私はもう、慌てたりすることはありません。冷静に「cp932」を書き加えることができます。何事もなかったかのように、処理を終わらせることでしょう。デスクの隅に置かれた、Pythonの入門書を見つめました。以前よりも、少しだけ親しみやすく感じられるようになりました。本の内容が、以前よりもすんなりと頭に入ってくるのです。
今では部署内で、頼りにされるようになりました。「文字コードのトラブルならあの人に聞け」と言われます。かつて自分を苦しめた、あの記号の洪水も懐かしいです。「繧ゅ§縺ー縺代」という文字を見ても、もう驚きません。「UTF-8でShift-JISを読んだのだな」と笑えるようになりました。そんな余裕が持てるようになったのです。解決策を知っているという自信が、私を支えています。新しいツールへの挑戦を、後押ししてくれています。
独学の道とこれからの武器
独学でPythonを学ぶ道は、決して楽ではありません。険しい道が続くこともありますが、得るものは大きいです。こうした小さな「壁」を乗り越えるたびに、成長できます。見える景色は、確実に変わっていくことでしょう。あの朝、文字化けを前に絶望していた自分に伝えたいです。その苦しみは決して無駄ではありません。それは将来、事務職としてのあなたの武器になるのだ、と伝えたいです。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。