
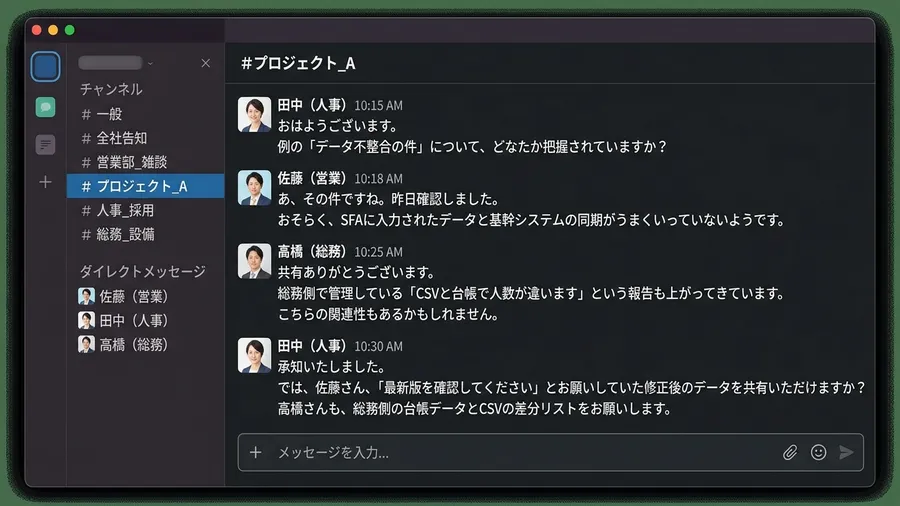
地味に精神を削る社員マスタ不整合
月末の金曜日、時計は18時を回っています。本来なら少し浮かれた気分になるはずの時間ですが、私の部署のチャットには決まって不穏な通知が灯ります。営業部からの「社員マスタ、最新版に更新されていますか? うちの台帳と人数が合わないんですが」という一文が、静かな押し付け合いのゴングとなっていました。
私たちの会社では、同じ社員情報を複数の部署が別々のExcelで管理していました。人事が大元の社員マスタCSVを出力し、それをもとに営業は営業成績と紐づく台帳を、総務は備品管理台帳を、経理は経費精算マスターを作るという流れです。問題は、人事異動や組織変更があるたびに、それぞれの部署が「自分のExcel」を手で更新しなければならないことでした。入力漏れ、所属部署の更新忘れ、退職者データの残置。誰かが間違いに気づくと、チャットでボールの投げ合いが始まります。「CSVが古いのでは?」「いえ、そちらの転記ミスでは?」。誰も真実を知らないまま、ただ空気だけが悪くなっていました。
月末データ不整合の手作業と疲弊
実際、月末のデータ不整合で営業と人事の間に挟まれ、深夜まで2つのファイルを目で突き合わせたことがあります。営業からは「数字が合わない」と急かされ、人事からは「CSVは出した」と言われる日々でした。どちらの言い分も分かるだけに、最終的には自分が手で差分を潰すしかありませんでした。この時間は非常につらいものでした。
結局、誰かが「じゃあ、こっちで確認します」と引き取るまで、このやり取りは終わりません。表面上は解決しても根本原因は残ったままなので、来月も同じことが起きてしまいます。この地味でありながら確実に精神を削る業務が、当時の私たちの日常でした。

二重入力が削る時間と信頼
データの二重入力がもたらす害は、単純な作業時間の無駄だけではありませんでした。もっと厄介なのは、部署間の信頼がじわじわと削られることです。データが合わないとき、本来は「どう再発を防ぐか」を話すべきなのですが、実際には「誰が間違えたか」の話になりがちでした。
「そっちの入力が遅いからだ」「元データが間違っている」といった言葉が飛び交い、悪意はなくても疑心暗鬼が空気を支配してしまいます。同じ情報を複数人が別々に入力する運用自体が、無言で「相手の入力を信用していない」と言っているのに近い状態でした。
新入社員の部署コードを誤って入力し、給与計算に影響が出かけたこともあります。あとで人事の初期配属リスト側にも古いコードが残っていたと分かったのですが、一度ミス扱いされると、しばらくは小さな変更でも疑われるような空気が残ってしまいます。こういう心理的コストは数字にしにくいものの、現場には確実に響いてくるものでした。
このとき計測したところ、ミス発覚から原因特定、修正、関係部署への共有まで平均で約2.7時間かかっていました。月に4回起きるだけで、実質11時間近くが消えていたことになります。二重入力は、時間と信頼を同時に削る運用でした。
正データ起点統一、協業とPython化
一方で、泥沼から抜ける第一歩は技術導入ではありませんでした。まずは「正データの起点は1か所だけ」と決めることでした。私たちは、人事が月初に出力する社員マスタCSVを唯一の正として定義しました。営業・総務・経理のExcelは、そこから派生した参照先という位置づけに変えたのです。
このルールが決まると、見る場所が1つになります。不整合が出たら、まずCSVを確認します。犯人探しではなく、「どこでズレたか」を一緒に追えるようになります。ここでようやく、部署間で同じ方向を向けるようになりました。
ルールが決まったあとで、転記作業をPython化しました。VBAでも可能ですが、CSVの扱いや将来の保守を考えてPythonを選んでいます。無料で始められるため、現場改善として動かしやすかったのも大きなメリットでした。
流れはシンプルです。人事CSVを読み込み、次に部門別Excel台帳を開きます。共通キーの社員番号で照合し、CSV側の最新値だけをExcelへ転記します。これを全社員分まわすという仕組みです。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
ログ管理による安心運用と作業効率化
重要なのは、転記そのものよりログ管理でした。更新した行に「更新日時」と「更新者(スクリプト名)」を必ず出力するようにしたのです。あとで「どこがいつ変わったか」を追えるので、運用の安心感が一気に上がりました。

この仕組みを作ってからは、毎月やることが固定化されました。CSVを置く、スクリプトを実行する、更新ログを確認する。以前は複数人で半日つぶれていた作業が、数十秒から数分で終わるようになりました。
部分自動化と例外処理
しかし、理想どおりにいかないのが現場データです。氏名ゆれ、空欄、旧部署コードはほぼ確実に出ます。ここを無視すると、スクリプトは簡単に止まってしまいます。
初回テストでは、CSVから消えた退職者がExcelに残っていて、照合時にキー未存在エラーが連発しました。結局その日は30分以上かけて手で整理しました。自動化の最初に「逆に仕事が増えた」と感じる典型的なパターンでした。
私たちが取った対策はシンプルで、例外専用シートを作ることでした。照合できなかった社員番号や空欄項目を自動で書き出し、処理本体は止めずに続行させます。担当者は例外シートだけ毎朝見ればいいようにしました。完璧な100%自動化ではなく、9割自動化+1割手当てにしたことで運用が安定しました。
さらに、【スクショ:Excelの「例外リスト」シート。列見出しは「社員番号」「エラー内容」「確認日」「対応状況」。旧コードや空欄が赤で表示されている。】
数字以上の効果。正データが変えた現場の空気
導入1か月で、手入力工程は人事CSV出力の1回に集約できました。転記と突合の手作業はほぼ消え、月間の関連残業は約31%減りました。数字だけでも十分な効果がありました。
でも、いちばん大きかったのは空気の変化です。月末チャットのトーンが明らかに変わりました。「データが合わないんですが」という非難が減り、「今月の更新完了。例外3件です」のような事実共有に置き換わったのです。犯人探しから、問題解決へと意識が移れた感覚がありました。
まず、【スクショ:更新ログ付きExcel。列に「社員番号」「更新項目」「更新日時」「更新者」が日本語で並び、整然と更新履歴が残っている。】
正データが1つだと決まっているだけで、確認の会話が非常にスムーズになります。疑いから始まらないことが、これほど効果的だとは思いませんでした。
小さく始めて運用で育てる現場改善
最初から全社横断でやっていたら、多分失敗していたはずです。営業部の1シートだけで始めたからこそ続いたのだと思います。小さく始めて、結果を見せて、他部署へ広げる。この順番が一番現実的でした。
実際、最初の1か月で「うちでも使えないか」という相談が増えました。仕組みよりも先に、運用の納得感が広がったのだと感じています。
【スクショ:朝のオフィス机。キーボード横のノートに「d73 自動転記チェック」「例外0件」と日本語メモが書かれている。】
この手の改善は作って終わりではありません。私たちは月1回、関係者で例外シートを10分だけ確認する時間を固定しました。頻出エラーがあれば入力ルールを直し、必要ならスクリプトを直す。これだけで、仕組みが形骸化しにくくなります。
もし、同じようにデータの押し付け合いで消耗しているなら、まずは「正データは1つ」と決めるところから試してみてはいかがでしょうか。大きな予算や派手なツールがなくても、1シートの自動転記から現場はかなり変わります。
回しながら直す運用と例外記録で現場改善
実運用では、最初の2週間だけでも「どの例外が何回出たか」を簡単に記録しておくと、改善の優先順位が見えやすくなります。私たちも最初は手探りでしたが、頻出する例外を3つ潰しただけで問い合わせが目に見えて減りました。完璧な設計を待たず、回しながら直す。この順番のほうが、非エンジニアの現場では続きやすかったようです。
ここが大きなポイントでした。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
関連書籍
業務効率化関連書籍を、手元で見返せる形にしておきたい場合
業務効率化は、いきなり大きく変えるより、手元の作業を1つずつ減らすほうが続けやすいです。考え方を見返せる本があると、次の一手を選びやすくなります。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。