
見えない日付形式の罠
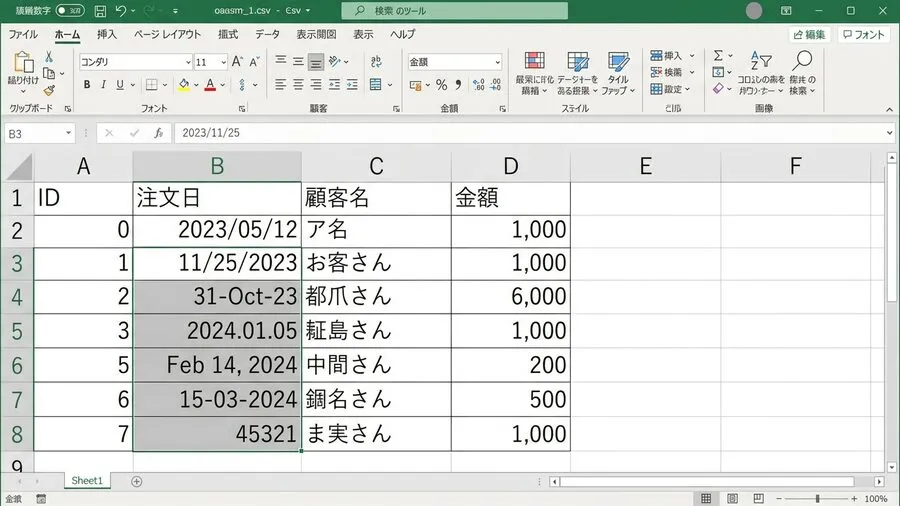
画面上の進捗バーが赤く染まります。それを見ると、胃の底が冷たくなる感覚に襲われます。総務や人事で働いている皆様には、覚えがあるかもしれません。数千件もの従業員データをシステムに流し込む作業があります。これは一ヶ月の集大成ともいえる大仕事です。それなのに、アップロードボタンを押した直後にエラーが出ました。画面には非情なメッセージが羅列されています。「1行目:日付の形式が不適切です」「2行目:日付の形式が不適切です」といった内容です。
それは、給与計算の締め切り直前のことでした。3000人分もの膨大な勤怠データを取り込もうとしていました。CSVファイルを用いて、基幹システムへ流し込む作業です。Excel上では、日付は完璧に見えました。「2023/10/01」と整然と並んでいます。しかし、システム側からは全件拒否されてしまいました。画面には「YYYY-MM-DD形式で入力してください」と表示されています。私は画面を二度見しました。マウスを握る手には、じっとりと汗がにじみます。結局、原因が全くわかりませんでした。1件ずつ手入力する悪夢が頭をよぎります。深夜のオフィスで一人、途方に暮れてしまいました。
Excelで見える日付の落とし穴
まず、不思議でなりませんでした。ExcelでそのCSVファイルを開いてみます。すると、どこからどう見ても日付は正しく入力されています。スラッシュで区切られた数字が、きれいに並んでいます。年、月、日が整然としているのです。それなのに、システム側は「形式が違う」と言い張ります。この乖離は、一体どこから生まれるのでしょうか。その原因について考えました。私たちは普段、Excelの画面を「見ている」だけです。しかし、その画面はデータの真の姿を覆い隠しています。いわば、フィルターのような役割を果たしているのです。
データ処理の世界では、目視による確認が通用しないことがあります。人間にとって「同じ」に見える日付もあります。しかし、コンピュータにとっては全く異なる文字列かもしれません。そのように認識されるケースは非常に多いです。この「見た目の罠」に気づくことが大切です。それに気づかない限り、エラーは解決しません。何度インポートを試みても、結果は同じことの繰り返しです。エラーの山を築くだけになってしまうかもしれません。
Excelの日付変換とデータ破損
なぜExcelは、これほどまでに私たちを惑わせるのでしょうか。その理由について説明します。それは、Excelが持つ「お節介」な機能にあります。この機能は非常に強力です。私たちは、CSVファイルをダブルクリックして開くことがあります。中身を一度確認するためです。このとき、Excelはセル内のデータを読み取ります。そして、それが日付らしいと勝手に判断します。その瞬間に、内部形式を書き換えてしまうのです。
次に、Excelにおける日付の扱いに注目しましょう。Excelにとって、日付は単なる「数値」に過ぎません。1900年1月1日を「1」と定めています。そこから何日が経過したかという、シリアル値で保持しています。画面に「2023/10/27」と表示されていても同じです。Excelの内部では「45226」という数字があるだけなのです。問題は、このシリアル値を保存する瞬間に発生します。CSVとして書き出すときに、予期せぬ変化が起きてしまいます。
Excel日付自動変換とデータ破損の罠
以前、前任者から引き継いだファイルがありました。マクロ入りのExcelファイルです。その中で、日付が突然変わってしまったことがあります。「45130」のような謎の5桁の数字になりました。セルの書式設定を「日付」に直せば、見た目は戻ります。しかし、CSVで保存してメモ帳で開くとどうでしょうか。ある時は「2023/10/1」になっています。またある時は「2023-10-01」になっています。保存するPCの環境によって、形式が変わってしまいます。この不安定さに、背筋が凍る思いがしました。
環境で変わるCSVのテキスト形式
CSVファイルは、本来はただのテキストファイルです。装飾も書式も存在しないはずのものです。しかし、Excelで保存を実行すると状況が変わります。そのPCの「ロケール設定」が影響してしまいます。地域設定に基づいた形式で、強制的にテキスト化されるのです。ある環境では「2023/10/27」となります。別の環境では「2023-10-27」となります。システム側が「YYYY-MM-DD」を厳格に求めていると大変です。スラッシュが混じった瞬間に、データはゴミになります。取り込み不可能な状態に陥ります。
この「勝手に変換される」という仕様が問題です。これが非エンジニアを苦しめる最大の原因になっています。Excelで開いて「よし、正しい」と確信します。しかし、その後の保存という一動作が原因です。それが実はデータを破壊しているのです。この現実は、なかなか受け入れがたいものがあります。善意で行った確認作業が、仇となってしまうのです。

Excelで躓く日付書式、Pythonで劇的改善
多くの人が、この問題を解決しようとします。Excelの「セルの書式設定」を使う方法です。表示形式を「YYYY-MM-DD」に変更し、上書き保存をします。しかし、次にそのファイルを開いたときに驚きます。また元のスラッシュ形式に戻っていることがあります。あるいは、システム側で相変わらずエラーが出ます。これは、Excelが保存時に再びお節介を焼くからです。ユーザーの意図を無視した形式で、書き出してしまいます。
ここで、新しい視点が必要になります。Excelというフィルターを通さない方法です。データを直接加工する技術を取り入れましょう。Pythonを使えば、それが可能になります。データを「見た目」ではなく「構造」として捉えます。そうすることで、正確に変換できるようになります。Excelの挙動に振り回されることがなくなります。
例えば、10,000行のCSVデータがあるとします。これをExcelで手動修正するのは大変です。検索と置換や書式変更を繰り返すと、数時間かかります。しかし、Pythonスクリプトなら一瞬です。一括変換の処理時間は、1分以内で終わります。圧倒的な作業時間の短縮が可能になります。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
Python datetimeで日付を統一
Pythonには、便利な道具が用意されています。日付を扱うための標準ライブラリ「datetime」です。これを使えば、バラバラな形式も怖くありません。どんなデータでも、一度コンピュータ用のオブジェクトにします。そこから、任意の形式へと再構築できるのです。人間の主観を排除した、正確な処理が行われます。
具体的には、「strptime」という関数を使います。これは「%Y/%m/%d」といったルールで解析する機能です。文字列を一度、日付データとして分解します。その後、「strftime」という関数を使います。これによって「%Y-%m-%d」という形式で書き出します。この工程を挟むことが重要です。Excelの気まぐれを排除した、純粋な変換が可能になります。
数時間の格闘を数秒で解決する技術
どれだけ書式設定をいじっても直らなかったCSVがあります。それをPythonの数行のコードに通してみました。すると、一瞬ですべての「/」が「-」に変わりました。ゼロ埋めされていなかった月日も整いました。「01」のように美しく整列したのです。それまでの数時間に及ぶ格闘が、嘘のように感じました。インポート作業は、わずか数秒で終わりました。画面には「正常終了」の緑色の文字が表示されました。
「コードを書く」と聞くと、身構えるかもしれません。しかし、やっていることは単純です。いわば、データの翻訳作業をしているだけです。Excelが勝手に解釈する余地を与えません。一文字ずつのルールを、厳格に指定します。この厳格さこそが、大切です。業務効率化を支える、強力な生命線となります。
pandasによる日付の自動統一
さらに厄介なケースも存在します。一つのファイルの中に、異なる形式が混在する場合です。「2023/10/1」と「2023-10-01」が混ざっています。さらに「20231001」まで含まれていることもあります。取引先や他部署から届くデータには、よくあることです。こうした表記揺れは、日常的に発生します。これらを手作業で統一するのは、苦行でしかありません。一つずつ探し出すのは、非常に時間がかかります。
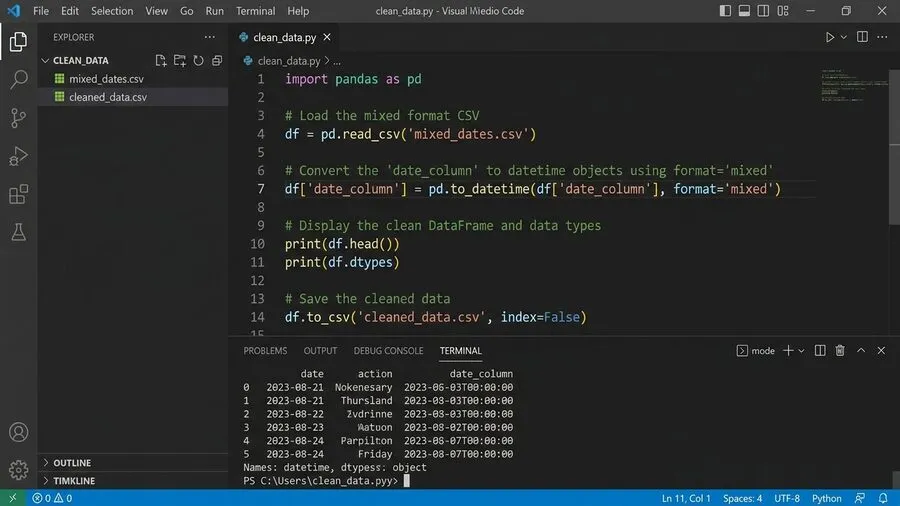
こうした複雑なデータ処理には、別の道具が役立ちます。Pythonの外部ライブラリ「pandas」というものです。pandasには、非常に強力な関数が備わっています。それが「pd.to_datetime()」という関数です。これを使うことで、煩雑な処理を自動化できます。
特に、pandas 2.0以降の機能が優秀です。「format=’mixed’」というオプションが導入されました。これを使うと、複数の形式が混在していても大丈夫です。pandasが自動で推測し、適切な日付に変換してくれます。解析できないほど壊れたデータがある場合も安心です。「errors=’coerce’」を指定すれば、エラーで止まりません。該当箇所を「NaN」としてマークし、処理を続けてくれます。
Pandas活用、日付形式の自動統一
具体的な手順について、整理してみましょう。まず、pandasでCSVファイルを読み込みます。次に、「pd.to_datetime()」を使います。これによって、混在した日付を統一形式に変換します。変換できなかったエラー行がないか、確認します。それらを検出して、手動で直すか削除します。最後に、希望する形式でCSVを書き出します。例えば「YYYY-MM-DD」といった形式です。
また、Excelファイルを直接読み込むこともできます。その際は「openpyxl」というライブラリを併用します。セルの値がどのような状態かを判定します。日付オブジェクトなのか、ただの文字列なのかを見極めます。それぞれの型に合わせて、適切に処理を分岐させます。これにより、Excel特有のシリアル値問題も回避できます。完全に制御することが可能になります。
データ整理を自動化する快感
5つの拠点から集まった勤怠表がありました。それらを統合した際の出来事です。各拠点で、日付の書き方がバラバラでした。ある拠点はスラッシュを使い、ある拠点は和暦でした。また、ドットで区切っている拠点もありました。それらを眺めて、絶望的な気分になりました。しかし、pandasの変換機能を試してみました。すると、9割以上のデータが一発で揃いました。標準的な形式に、きれいに整ったのです。
残りの数件のエラーだけを確認すれば済みました。目視でチェックする範囲が、劇的に減ったのです。そのとき、真の意味で道具を使いこなす快感を知りました。この自動化の仕組みを、一度作っておきましょう。そうすれば、毎月の作業はボタン一つで終わります。面倒なデータクレンジングから解放されます。
受領したCSVを、特定のフォルダに放り込みます。そして、スクリプトを実行するだけです。それだけで、システムが喜んで受け付けるファイルができます。完璧なインポート用ファイルが、すぐに出来上がります。作業のストレスが、大幅に軽減されるはずです。

日付形式エラーは解釈のズレ。Pythonでデータ制御
まず、エラーメッセージについて考えましょう。「日付の形式が違います」という言葉です。これは、単なる入力ミスへの指摘ではありません。それは、解釈のズレを警告しているのです。私たちが使うExcelと、待ち構えるシステムとの間のズレです。私たちはつい、画面に見える文字を信じてしまいます。それがそのままデータだと思い込んでしまいます。しかし、CSVというテキストの裏側は複雑です。
エンコーディングやロケールの影響があります。内部シリアル値といった仕組みも潜んでいます。日付を扱う上で、大切なことがあります。自分の目を過信しないことです。データの「中身」がどう構成されているかを疑いましょう。どのようなコードポイントで動いているのかを確認します。この姿勢が、トラブルを防ぐ鍵となります。
国際標準を意識したデータ管理
Pythonやpandasを使うメリットは多いです。単に作業スピードが速くなるだけではありません。データの正体を正確に把握するための手段です。自分の制御下に置くための強力な武器になります。ISO 8601という国際標準の形式があります。すなわち「YYYY-MM-DD」という書き方です。これを常に意識するようにしましょう。Excelの自動変換に頼らないことが重要です。自らの手でフォーマットを定義してみてください。その一歩が、不毛なエラーとの格闘を終わらせます。あの苦労は、もう過去のものになるはずです。
心を削る業務のPython自動化
業務の自動化には、進め方があります。まず、地味で目立たないトラブルを潰しましょう。確実に心を削るような作業を減らすのです。日付形式の正規化は、小さな一歩かもしれません。しかし、その成功体験を積み重ねることが大切です。それが、会社全体のDXへと繋がっていきます。確かな道筋を築くことになるのです。
今では、CSVを取り込む前に工夫をしています。必ず自作のスクリプトを通すようにしました。「バリデーションスクリプト」と呼んでいます。もし形式が違う行があれば、赤字で警告が出ます。インポート作業の前に、間違いに気づける仕組みです。これを導入してから、変化がありました。システム側のエラーログを見ることは、一度もありません。
上司からは、「最近作業が早いな」と声をかけられます。とても誇らしい気持ちになります。しかし、その裏側には秘密があります。Pythonが完璧な下準備をしてくれているのです。このことは、ここだけの秘密にしておきます。技術を味方につけることで、日々の業務はもっと楽しくなります。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうかを判断できます。VBAかPythonか、選ぶ基準もわかります。最初に避けるべき落とし穴をまとめました。実務で迷うポイントを網羅しています。メールアドレスだけで、すぐに受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルを自動で選ぶ機能があります。部署名のゆれを正規化する機能もあります。さらに、CSVの文字コードを確認できます。これら3本のセットをご用意しました。今週の作業を楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。