
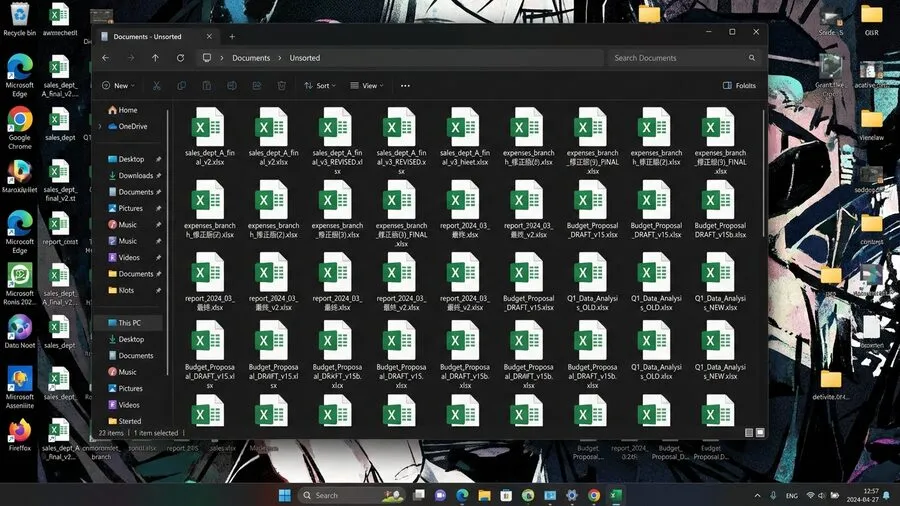
月末データ統合の悲劇
月末のオフィスは、しんと静まり返っています。フロアには、マウスの無機質なクリック音が響きます。キーボードを叩く音だけが、静寂の中に消えていきます。マウスを握る右手の親指の付け根は、じりじりと熱を持っています。瞬きを忘れた目は、ひどく乾ききっていました。経理や総務、人事などの管理部門にいると、必ず回ってくる作業があります。それが「データの回収と統合」という非常に重い業務です。各部署の担当者が入力した実績ファイルや申請書が集まってきます。ファイルの数は10個程度なら、まだ良い方かもしれません。しかし、拠点が多い会社では、数十個ものExcelファイルが届きます。それらはファイルサーバーやメールの添付で、次々と送られてくるのです。
まずは届いたファイルを開きます。必要なデータの行を選択して、コピーを行います。次に全社統合用のマスターファイルを開きます。データの最終行まで画面をスクロールさせます。そこで慎重にペースト作業を行います。最後にファイルを閉じます。そこには創造的な要素は一切ありません。ただひたすらに、右手と左手を動かし続けるだけの作業です。このような単純な繰り返しが、何度も続きます。10部署分の統合に、毎回3時間から4時間もかかっていました。たったこれだけの作業のために、貴重な時間が虚しく溶けていきます。その様子を、私はいつも肌で感じていました。
現代オフィスのExcel悲劇
まず、送られてくるファイルは決して完璧ではありません。不要な空行が含まれていることもあります。セルが謎の書式で黄色く塗られている場合もあります。提出期限を過ぎてから、修正の連絡が入ることも日常茶飯事です。「数字を間違えたので、ファイルを差し替えてください」とチャットが飛んできます。各部署からは、様々な名前のファイルが五月雨式に送られてきます。「提出用_最終_修正版(2).xlsx」といった命名規則を無視したファイルです。それらをひとつずつ開いてコピペしていると、ミスが起こります。いつの間にか元のファイルの行と列がズレていても、気づくことはできません。
3時間分の作業がすべて無駄になったときの絶望感は、言葉にできません。胃が鉛のように重くなり、体中の力が抜けていくようでした。モニタの強烈な光が、疲れ切った目に深く突き刺さります。これは、誰か特定の人が悪いわけではありません。Excelという便利すぎるツールが生み出した事態です。現代のオフィスにおいて、避けられない悲劇だと言えるでしょう。
億単位のコピペミス、手作業からの卒業
コピペ作業の恐ろしいところは、作業時間が長引くことだけではありません。人間の集中力を徐々に削り取り、致命的なミスを誘発することにあります。機械のように正確な処理を、何百回と繰り返すことは不可能です。人間の脳の構造上、そのような作業には限界があるのではないでしょうか。
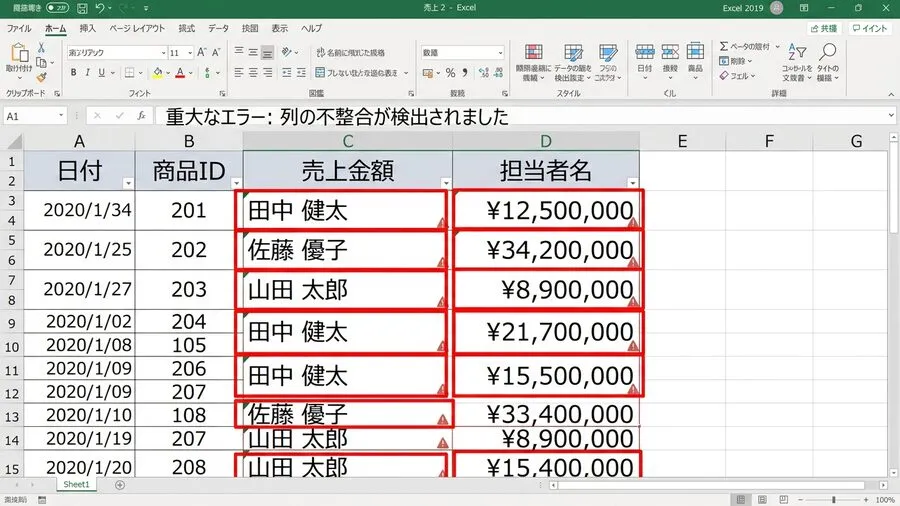
あの日の失敗は、今でも鮮明に思い出すことができます。深夜22時、フロアの照明が半分落ちた薄暗いオフィスでのことです。私は最後のデータを貼り付け、上司への報告用フォルダに保存しました。疲労で目のピントが合わず、画面の数字が二重に見えていたほどです。翌朝、血相を変えた上司から会議室に呼び出されました。原因は、非常に単純な範囲指定のミスでした。ある部署のデータを貼る際、B列のデータをC列にズラしてしまったのです。その結果、金額の桁がひとつズレて計算されてしまいました。全社の売上総額が、億単位で狂っていたのです。
手作業の限界と決別
手作業には、どうしても限界があります。どれだけ気をつけても、人間は疲労すれば見落としをします。ダブルチェックの体制を敷いても、手元が狂うことは防げません。謝罪のために作った再発防止策には、虚しい言葉を並べました。「今後は指差し確認を徹底する」と書くしかありませんでした。しかし、仕組みがアナログなままでは解決しません。人間の注意力だけで品質を保とうとする構造が、間違っています。物理的に手でコピーする行為そのものを、根絶する必要があります。そうしない限り、同じ悲劇は何度でも繰り返されるでしょう。この日、私は二度と手作業で統合しないと、心に強く誓いました。
Pythonで複数Excel結合の自動化
手作業を撲滅するために選んだ武器は、Pythonでした。プログラミング言語を使って、作業を自動化することにしました。マクロ(VBA)を使う選択肢もありましたが、懸念がありました。VBAは動作中に画面が点滅し、エラーが起きることもあります。その点、Pythonにはデータ処理に特化した機能が豊富に揃っています。やりたいことを、驚くほど少ない記述で実現できるのが魅力です。
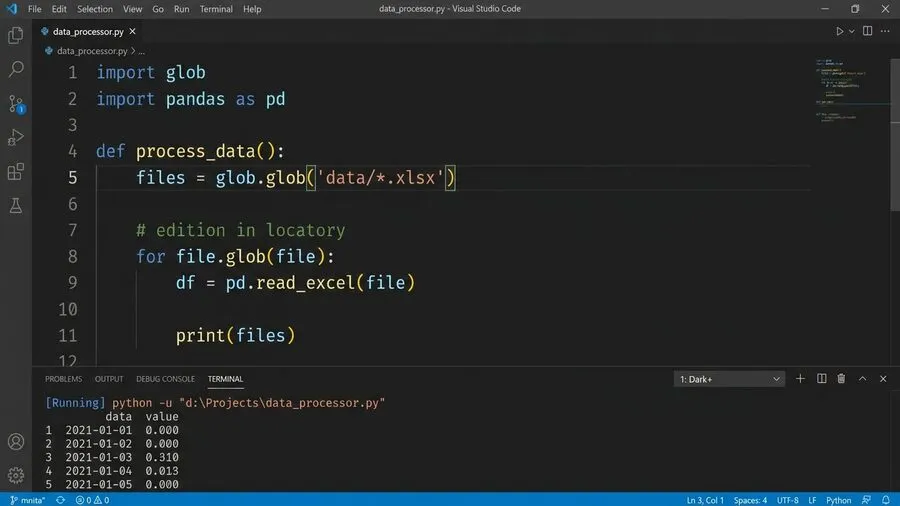
ここで主役となるのが「glob」と「pandas」です。これらは二つの便利なモジュールと呼ばれます。globは、パソコン内のフォルダを自動で巡回してくれます。指定した条件に一致するファイルを、瞬時に見つけ出す機能です。
glob.glob('フォルダパス/*.xlsx')これでファイルの一覧を自動で取得します。これは手作業で言うところの、目視確認にあたります。フォルダを開いて対象のファイルを探す手間が、一瞬で終わります。
次に、pandasという非常に強力な機能を呼び出します。
pd.read_excel()PythonによるExcelデータ結合の高速化
この命令は、各Excelファイルを読み込むために使います。データをDataFrameという形式で読み込みます。これは、Excelのシートを仮想的なメモリ空間に広げたものです。人間がマウスで操作する代わりに、計算エンジンが直接処理します。これにより、極めて高速なデータ操作が可能になります。
そして、最後に登場するのがこちらの関数です。
pd.concat()これは、バラバラの表データを縦に結合する役割を持ちます。Pythonを導入した後は、実行時間が約30秒に短縮されました。人間が手作業で行っていた重労働を、プログラムが肩代わりします。メモリ上で瞬時に作業を完了させるのが、プログラムの持つ力です。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
Excelファイル結合コード解説
理屈はさておき、実際のコードを見てみましょう。そのシンプルさに、きっと驚かれるはずです。PythonでExcelを操作するには、準備が必要です。openpyxlというパッケージを事前にインストールしておきましょう。コマンドプロンプトなどで簡単に導入することができます。
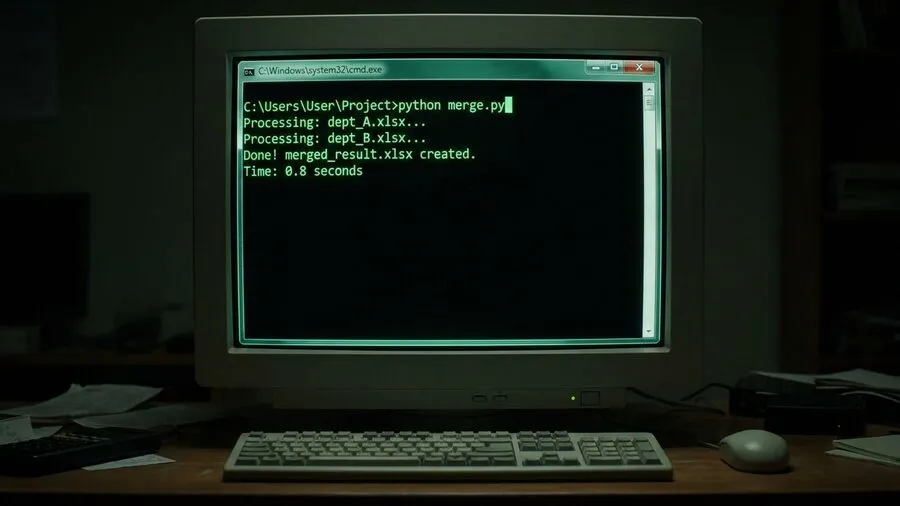
import glob import pandas as pd file_list = glob.glob('target_folder/*.xlsx') df_list = [] for file in file_list: df = pd.read_excel(file) df_list.append(df) df_merged = pd.concat(df_list, ignore_index=True) df_merged.to_excel('merged_result.xlsx', index=False)
Excel結合のPython自動化
たったこれだけの行数で、数時間の作業が完了します。Pythonは視覚的な画面を持たないため、少し不安かもしれません。しかし、やっていることは手作業の忠実な再現です。まずはファイルをリストとして集め、順番に取り出していきます。
リストの中身を、一つずつ処理するために「for文」を使います。取り出された各ファイルは、DataFrameとして読み込まれます。それらは「df_list」という名前の箱に、次々と追加されます。すべてのファイルを読み終えたら、一気に縦方向へ結合します。ここで指定する設定により、行番号が綺麗に振り直されます。これにより、結合後の表が非常に見やすくなります。最後に、結果を新しいExcelファイルとして保存します。「index=False」という指定を忘れないようにしましょう。これを指定しないと、余計な行番号まで書き出されてしまいます。
Excelデータ処理の罠と対策
コードが完璧であっても、元のデータが完璧とは限りません。ここで挫折する最大の原因は、データの状態にあります。人間が見ている表と、プログラムが認識するデータには溝があります。各部署が自由に入力したExcelには、多くの罠が潜んでいます。それらは、プログラムの正常な動作を妨げる厄介な存在です。
特に注意すべきなのは、列名のズレです。私が以前コードを実行した際、困ったことが起きました。完成したファイルを開くと、データが階段状にズレていたのです。原因は「備考」と「備 考」という表記の違いでした。半角スペースがあるだけで、別の列として認識されてしまいます。何が起きたか分からず、その時は冷や汗が止まりませんでした。結局、その日は手作業で修正を行い、終電を逃しました。今でも思い出すだけで胸が痛む、苦い記憶のひとつです。
列名の表記揺れを防ぐ方法
pandasの機能は、非常に厳密に動作します。列名が1文字違うだけで、別のデータだと判断されます。この問題を回避するには、結合前に列名を揃えることが有効です。読み込みの直後に、列名を一括で設定し直す処理を挟みましょう。共通の列名を指定すれば、データのズレを完全に防げます。これにより、統合後のデータの整合性を保つことが可能になります。
PandasでのExcel読み込み:シートと空白行の対策
二つ目の罠は、シート名のバラつきによる誤読み込みです。Pythonは、標準では一番左にあるシートを読み込みます。もし誰かが作業用シートを左端に置いていたら、失敗します。無関係なデータが混入し、集計が台無しになってしまうでしょう。これを防ぐには、読み込むシート名を明示的に指定します。特定の名前を指定することで、常に正しいデータを取得できます。
三つ目の罠は、意図しない空白行の混入です。見た目は空でも、データが残っている場合があります。スペースや罫線があるだけで、プログラムはデータだと誤認します。これを解決するには、クリーニング処理を追加しましょう。全ての項目が空である行を、自動で削除するように設定します。これによって、精度の高いマスターデータが完成します。
Pythonによる集計・レポート自動化
ファイルの結合が終わっても、実務はそこで終わりません。結合されたデータを元に、合計値を計算する作業があります。部署ごとの売上や、月別の経費推移などを算出する必要があります。多くの場合、ここからまたExcelでの作業が始まります。ピボットテーブルを使い、手動で集計を行うことになるでしょう。
しかし、その集計作業もPythonの中で完結させることができます。結合したデータに対して、集計用の機能を使ってみましょう。これは、Excelのピボットテーブルと同じ役割を果たします。部署名を基準にして、売上金額を合計する処理も簡単です。複雑に見える計算も、わずか1行のコードで実現できます。生のデータを保存するだけでなく、レポートも同時に出力しましょう。美しく整えられた表を、別のシートに書き出すことが可能です。こうして作り込めば、手作業が介入する余地は完全になくなります。
ルーティン業務の自動化、感動と解放
スクリプトを自動実行するように設定しておけば、非常に楽になります。月末の朝に出社したとき、既にレポートができている感動は格別です。かつての長いコピペ地獄からは、完全に解放されました。同僚が慌ただしく作業する横で、穏やかに朝を過ごせます。コーヒーの香りを楽しみながら、澄んだ空気を感じることができました。最初はエラー画面の赤字に、心が折れそうになるかもしれません。ですが、一度仕組みを作れば、プログラムは忠実に動いてくれます。文句一つ言わずに、毎月ミリ秒単位の正確さでこなしてくれます。手作業の限界を感じたときこそ、チャンスです。終わらないルーティンの連鎖を、今こそ断ち切りましょう。
完全版のご案内
フォルダ内のExcelを1つに自動結合するPython(コピペ完全版)
部署ごとのファイルを自動で1つにまとめる流れを、コピペで動くコード全文つきでnoteに整理してあります。シート名や列名がそろっていないファイルが混ざっていても列ズレしない形にしてありますので、実務でそのまま回したい方は参考にしてみてください。
関連リンクとチェックリスト
無料プレゼント Excel業務を自動化する前に確認するチェックリスト(PDF) 自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。 ¥980 ミニキット
無料でチェックリストを受け取るコピペで動かせる3スクリプト+自動化チェックリスト 最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。 著者はこうして解決の糸口を見つけた 著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
ミニキットを見る(¥980)学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。