
請求書社名誤記、自動化の闇
受話器の向こうから、不機嫌な声が聞こえてきました。その声を聞いた瞬間に、背筋を冷たい汗が流れます。私は月末の多忙な時期を乗り切るために準備をしていました。丹念に時間をかけて、請求書の自動出力システムを組み上げたのです。しかし、その稼働直後にトラブルが発生しました。得意先の経理担当者から、一通のクレームが届いたのです。「会社名が間違っていますよ。うちは前株ではなく後株です」という内容でした。
ご指摘の内容は、法人格である「株式会社」の位置についてでした。ビジネスの世界において、相手の正式名称を間違えるのは致命的です。これは非常に重大なマナー違反に当たります。ましてや、請求書は金銭のやり取りが発生する公式な文書です。そこでの誤記は、そのまま自社の信用問題に直結してしまいます。
私はまず、送付済みのPDFファイルの内容を確認しました。確かに宛名の表記が「株式会社〇〇」になっていました。正しい社名は「〇〇株式会社」です。頭に血が上り、心臓が嫌なリズムで跳ねるのを感じました。私は急いで謝罪し、再発行することを約束しました。電話を切った後、重苦しい胃の痛みを感じました。「自動化プログラムのどこでバグったのか」と、途方に暮れてしまいました。
再発行作業という精神的な重圧
VLOOKUPを欺く見えない文字の罠
再発行の手続きは、想像以上に精神を削る作業です。まずは元のデータを修正しなければなりません。その上でPDFを作り直し、経理部長に頭を下げます。再承認のハンコをもらう工程も必要になります。私はPythonやExcelの関数を駆使してきました。残業を減らすために努力を重ねたはずです。それなのに、たった一つの文字のズレがすべてを台無しにしました。

見えない文字によるデータ不整合
上司に事情を説明する時は、非常に気まずい思いをしました。自分が書いたコードに対する自信も失われていきます。「手作業で確認したほうがマシだったのではないか」という言葉が浮かびます。その思いが、頭の片隅を何度もかすめました。しかし、ここで逃げるわけにはいきません。二度と同じミスを起こさないために、原因を突き止める決意をしました。システムの闇に潜る覚悟を固めたのです。
見えない文字とVLOOKUPの罠
私は慌てて、基幹システムから元データをダウンロードしました。さらに、請求書発行用のExcelマスタを同時に開きました。データを詳細に確認していくと、奇妙な現象に直面しました。顧客IDをキーにしたVLOOKUP関数は、正常に動作していたのです。一切のエラーを吐き出すことなく、値を返していました。「株式会社〇〇」と「〇〇株式会社」が混在している状況です。それなのに、Excelの関数は正しく値を引っ張っているように見えます。目視で確認する限り、マスタには正しく登録されているように見えました。
システム連携を阻む不可視文字
ところが、PythonのライブラリでPDFを生成する際に異変が起きました。一部の顧客データだけが、意図せず後株に変わっていたのです。また、社名の中に妙な空白が混じることもありました。Excelが画面上で表示している文字と、プログラムが読み取る文字が違います。そんな馬鹿なことがあるはずがない、と私は思いました。何度もセルをダブルクリックして、中身を覗き込みました。画面に顔を近づけても、表示されているテキストは同じに見えました。

VLOOKUP関数は、検索値と完全に一致するデータを探す仕組みです。一致していると見なされているなら、データは同一のはずです。しかし、「N/A」と表示されるべき場所で、関数は平然と値を返します。私はCSVのエンコード設定を疑いました。あるいはPDF生成ライブラリのフォント設定を疑いました。こうして、見当違いの場所を数時間も探し回る羽目になったのです。
見えない文字によるデータ不整合
文字コード不一致の落とし穴
私は疑心暗鬼に陥りながら、隣の列にLEN関数を入力しました。文字列の長さをカウントするためです。目に見えない余計なスペースがないか確かめるためでした。Enterキーを叩いた瞬間、信じられない数字が表示されました。目視では同じ10文字に見える社名です。しかし、LEN関数の結果は10と11で分かれていたのです。一方で、まったく同じに見える「株式会社〇〇」という文字列がありました。しかし、上の行は10を返し、下の行は11を返しています。
私は空白を取り除くTRIM関数を試しました。しかし、結果の数字は変わりませんでした。次に、制御文字を消すCLEAN関数を通しました。それでも、結果はピタリと同じままでした。どこかに、人間の目には見えない何かが潜んでいます。コピーしてテキストエディタに貼り付けてみました。それでもやはり、見た目の違いは判別できません。そこで、「A=B」を厳密に判定するEXACT関数を使いました。すると、無慈悲にも「FALSE」の文字が返ってきました。

システム連携の文字数不一致
文字コード不一致、データ連携の落とし穴
手入力で「株式会社〇〇」と打ち直してみました。すると、LEN関数は正しい数字を返しました。しかし、システムからエクスポートしたデータを使うと狂います。数百件のデータを手作業で打ち直すわけにはいきません。マウスを握る手が、じっとりと汗ばんでいくのを感じました。窓の外が暗くなっていくのを見つめます。帰宅の時間が遠のいていく絶望感を味わいました。手作業のコピペなら、問題は発生しないのです。
しかし、システム間のデータ連携をすると破綻してしまいます。この見えない壁の正体を突き止めなければなりません。そうしない限り、自動化は永遠に使い物になりません。文字が同じなのに、データの長さが違います。この矛盾を抱えたまま、データはシステムを流れていきました。そして最終的に、請求書の宛名という最悪の場所で暴発したのです。
隠れた文字コード不一致
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
文字コードの地雷原、Pythonでデータ浄化
原因は、文字コードの世界に深く根付いていました。社内システムAと社内システムBで、文字の扱いが異なっていたのです。同じ記号を入力したつもりでも、裏側のUnicodeが違っていました。例えば、「・」という中黒にも複数のコードがあります。また、「-」という全角ハイフンも同様です。さらに、全角スペースと半角スペースの違いも影響します。これらは人間の目には同じ記号に見えます。しかし、コンピュータにとっては全くの別物です。
コピー元のシステムによって、入力されるコードはバラバラになります。顧客が入力したWebフォームの仕様も関係します。MacとWindowsのキーボードでも、内部コードが異なる場合があります。このように、データが作られる環境によって差異が生じていました。これこそが、目に見えない不一致の正体だったのです。

見えない文字、データ連携の落とし穴
見えないデータ不一致をPythonでマスタ浄化
ExcelのVLOOKUPは、全角と半角を曖昧に処理することがあります。特定の条件下では、それらを一致していると見なすのです。そのため、画面上では問題ないように見えていました。しかし、Pythonのプログラムにデータを渡した瞬間に状況が変わります。厳密な文字列処理を行うため、隠れていた不一致が牙を剥きました。前株や後株の配置が狂う原因も、ここにありました。Webフォームでのスペース混入や、システム移行時のコード変換が原因です。社名の前に、ゼロ幅スペースという透明な文字があるケースもありました。
データ連携という行為は、文字コードの地雷原を歩くようなものです。私はその事実に、ようやく気がつくことができました。
Python unicodedataでデータ浄化
Pythonでマスタデータ正規化
この地雷を撤去するには、すべての文字を標準化するしかありません。ExcelのSUBSTITUTE関数で置換するのは、現実的ではありませんでした。異体字のパターンは、星の数ほど存在するからです。新しい地雷が見つかるたびに、数式を直すのは大変な作業です。ここで救世主となったのが、Pythonの標準ライブラリでした。unicodedataという便利なツールがあるのです。
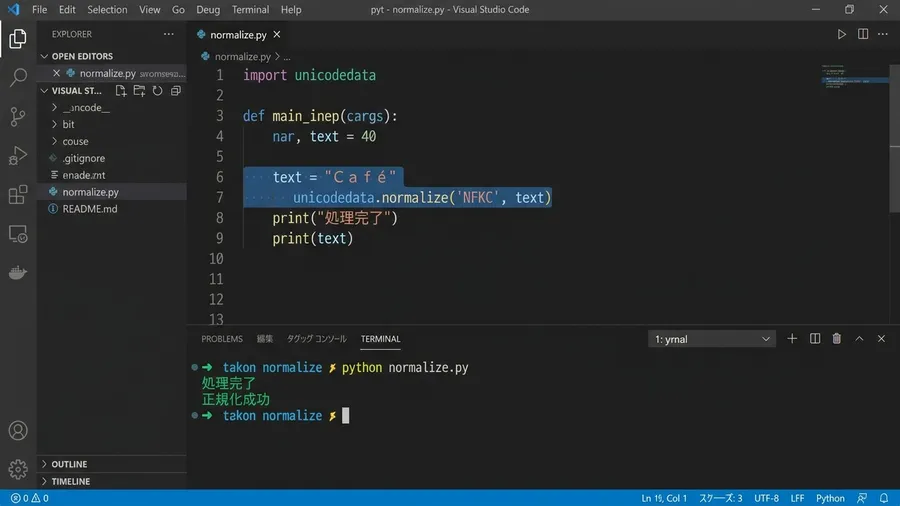
私は一行のコードを書きました。unicodedata.normalizeを使用するコードです。これだけで、全角英数字は半角へと変換されます。半角カタカナは全角へと統一されます。さらに、特殊なスペースも通常のスペースに変わります。NFKCと呼ばれる正規化の仕組みを活用しました。これによって、Unicodeの複雑な異体字を力技で統一できるのです。
会社名マスタ、秒速浄化で得た「正しいマスタ」
Pythonでマスタデータ正規化の実践
私はVSCodeを開き、正規化スクリプトを作成しました。数千件に及ぶ会社名マスタを一気に読み込みます。スクリプトを実行すると、一瞬で処理が完了しました。出力されたCSVを確認し、LEN関数の値をチェックしました。すべての文字数が綺麗に揃っていました。それを見た時、モニターの前で思わず声が出ました。数日間にわたる胃の重たさが、すっと消えていきました。
目視確認と手作業での修正には、月間15時間ほどかかっていました。それがスクリプトの実行により、わずか数秒に圧縮されました。正規化されたデータを使い、表記の統一ルールを書き加えました。前株や後株の分離も、Pythonの置換処理で自動化しました。環境依存文字である「㈱」なども、安全に置換できました。文字コードという根源的な部分で、データを浄化できたのです。ようやく「正しいマスタ」を手にすることができました。もうExcelの曖昧な仕様に振り回されることはありません。
Pythonでマスタデータ正規化
マスタデータ品質の肝、Pythonで自動正規化
人間の目視確認は、文字コードの前では全く無力です。日常的に使っているExcelも、常に真実を映すわけではありません。自動化プログラムが謎のエラーを出した時、原因を探すのは困難です。私たちは、ついツールのバグを疑ってしまいがちになります。しかし、本当のボトルネックはデータの質に潜んでいます。今回のトラブルを経て、私は登録時に正規化を行う仕組みを作りました。見えないノイズを入り口で弾くようにしたのです。その結果、後工程のシステム連携が劇的に安定しました。
Excelが見落としてしまうズレを、Pythonの厳格な処理が補います。もう二度と、前株と後株の違いで冷や汗をかくことはありません。そう心から思えるようになりました。システム化を進めるほど、データの潔癖さが求められます。あなたの管理するマスタデータは、今日も正しく保たれていますか?この問いを、私は胃の痛みとともに学びました。それは、エンジニアとしての貴重な経験となりました。
Pythonスキルアップの次の一歩
関連リンクとチェックリスト
私は藁をもすがる思いで、インターネットの海に飛び込みました。様々なキーワードを組み合わせて、何度も検索を繰り返しました。「Excel 見えない文字」や「LEN関数 違う」といった言葉です。すると、あるフォーラムで一つの投稿を見つけました。私と全く同じ現象に悩んでいる人がいたのです。その投稿には、見慣れない専門用語が並んでいました。全角スペースの違いや、改行コードといった言葉です。
私の場合は、一般的な関数でも解決しませんでした。そのため、もっと根深い問題であると直感しました。さらに調査を進めると、「文字コード」という言葉に行き着きました。これは、コンピューターが文字を認識するためのIDカードのようなものです。異なるコードで保存されたデータは、別物として扱われます。たとえ見た目が同じでも、コンピューターには伝わりません。その説明を読み、頭の中で点と点が繋がり始めました。
システム間の文字コード変換エラー
システムから出力されるファイル形式は様々です。CSVはUTF-8で、ExcelはShift_JISという場合も多いです。さらにPythonで扱うデータも、別の形式になることがあります。データが様々なシステムを経由する中で、変換が起きています。その過程で、不一致が生じていたのかもしれないと考えました。この仮説が、今回の問題解決への大きなヒントとなりました。
関連書籍
Python業務自動化関連書籍を、手元で見返せる形にしておきたい場合
Pythonやデータ処理の自動化は、作りながら同じ基礎を何度も確認する場面が多いです。手元で見返せる本があると、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)