
座標指定抽出の落とし穴
月末の静まり返ったオフィスでの出来事です。空調の低周波音だけが、やけに響いていました。薄暗いモニターの光に、顔が照らされています。私は、数百枚に及ぶ請求書PDFと向き合っていました。自動化のためにPythonスクリプトを導入しました。しかし、それが突然エラーを吐き出したのです。その結果、バッチ処理が完全に停止してしまいました。

エラーの箇所を特定したときのことです。私は思わず、その場に立ち尽くしてしまいました。原因は明白でしたが、あまりにも理不尽な内容でした。抽出した金額データに、文字が混ざっていたのです。なぜか隣接する「品目名」の文字が入っていました。原因の特定には、3時間もかかりました。PDFを開き、スクリーンショットを撮りました。画像編集ソフトに貼り付けて、ピクセル数を数えました。非常に不毛な作業を強いられた経験があります。
PDF座標抽出の落とし穴
まず、手作業のコピペ地獄から抜け出すことにしました。そのために、Pythonでテキストを抜く仕組みを作りました。特定の位置を指定して抽出する仕組みです。当初は、これが完璧に機能していました。PDF上の座標を、ピクセル単位で厳密に指定しました。必要な数字だけを、正確に拾い上げる設計です。テスト環境では、無事にグリーンライトが点灯しました。すべてのデータが、Excelへきれいに転記されました。そのときは、なんとも言えない万能感に包まれたものです。
しかし翌月の締め日に、その脆さが露呈しました。取引先が、発行システムをアップデートしたようです。人間の目には、先月と同じフォーマットに見えました。印刷して重ね合わせても、気づかないレベルの変化です。ですが、PDF内部のデータは異なっていました。全体が上に3ピクセル、左に2ピクセルずれていたのです。
枠ずれが招くシステム崩壊
この数ピクセルの余白変更が、致命傷となりました。抽出枠は、座標でハードコーディングされていました。その枠が、本来の金額欄から微妙にはみ出したのです。そして、隣にある文字列を巻き込んでしまいました。結果として、データベースには意味不明な値が入りました。これにより、経理システムの集計処理は完全に崩壊しました。
そのとき、冷や汗が背中を伝ったのを覚えています。鼓動が早くなり、強い不安に襲われました。上司へどう報告すべきかを想像しました。それだけで、胃が鉛のように重くなりました。結局その夜は、データの復旧作業に追われました。スクリプトが破壊した1000件のデータを直すためです。深夜まで手作業で、目視確認と修正を続けました。画面を見続ける目は、ひどく霞んでいました。マウスを握る右手は、腱鞘炎の一歩手前でした。
座標指定による抽出は、非常に厄介な性質があります。エラーを出して止まるなら、まだ良い方です。最悪なのは、間違ったまま処理を続けることです。プログラムは、無言で誤ったデータを処理し続けます。人間ならすぐに気づく変化を、検知できません。これが、絶対座標に依存した自動化の恐ろしさです。
PDF座標指定の罠と限界
なぜ、座標指定のコードは失敗しやすいのでしょうか。根本的な原因は、PDFの性質にあります。私たちは、このフォーマットを少し誤解しています。

画面上の表を見ると、私たちは無意識に錯覚します。Excelのような「セル」があると思い込んでしまうのです。「A1セルに日付があり、B1に金額がある」と考えがちです。しかし、PDFの内部にはセルの概念がありません。
PDFは、本来「電子の紙」として作られたものです。紙の見た目を再現するためのフォーマットに過ぎません。内部データは、絶対座標に対する描画命令の羅列です。「この位置に、この文字を描画しろ」という指示です。そんな指示が、内部では延々と書かれています。バラバラの文字スタンプが、白紙に押されている状態です。そこには論理的な「表」など、どこにも存在しません。ただインクの配置データがあるだけなのです。
絶対座標の限界と保守の泥沼
そこに、無理やり抽出枠を設定するのは危険です。物理的なナイフで、紙を切り取るようなものです。プリンタドライバが変われば、位置はずれます。システムが更新されれば、全体の位置が変わります。すると、切り取るべき要素は枠外へ消えてしまいます。会社ごとに、内部的な開始座標が違うこともあります。左下を原点とするか、左上を原点とするかの違いです。そんな環境で絶対座標を信じるのは、不安定です。砂の上に城を建てるような行為かもしれません。
これこそが、ハードコーディングの限界です。特定の環境でしか、この仕組みは成立しません。外部の変化が起きれば、すぐに壊れてしまいます。そのたびに、ソースコードを修正することになります。抽出枠の数値を微調整するテストの繰り返しです。自動化で時間を生むはずが、保守に追われます。神経をすり減らす、新たな業務の始まりです。
この底なし沼から、抜け出す必要があります。そのためには、アプローチを根本から変えましょう。「画面のどこにあるか」という点に執着してはいけません。
PDF構造解析:ズレに強い堅牢抽出
『点』で位置を特定するのをやめましょう。PDFの中にある『構造』を捉え直すのです。これが、ズレの呪縛から逃れるための最強の手段です。

見た目はただの直線と文字の集まりに見えます。しかし、プログラムの目線で正しく解析しましょう。すると、それは意味を持ったオブジェクトになります。要素の背後にある関係性を、読み解く必要があります。どこにテキストの塊があり、どこに線があるかを見ます。それらを論理的に把握する手法へと切り替えます。
構造解析へのシフトは、大きなパラダイムシフトです。まさに、天動説から地動説へ変わるほどの変化です。
これを実現するのが、pdfplumberというライブラリです。このツールは、PDFを画像として扱いません。ドキュメントの内部構造を、丁寧に解析します。テーブルの罫線となる直線を検出してくれます。その交点から「セル」の領域を割り出すのです。論理的に範囲を特定する機能を持っています。
見た目に惑わされない、堅牢な表構造認識
この仕組みには、素晴らしいメリットがあります。全体が上下左右にズレても、問題ありません。表を構成する線の相対関係が保たれれば良いのです。それだけで、正確に構造を認識することができます。余白の幅や解像度が変わっても、影響を受けません。表は、常に独立した表として認識され続けます。
もはや、数ピクセルのズレに怯える必要はありません。線で囲まれた領域の中のテキストを抜く手法です。これにより、一つのブロックとして安全に取り出せます。表面的な見た目の変化には、もう惑わされません。背後にある骨組みを、直接掴みに行くのです。これが、堅牢な自動化を築くための絶対条件です。
PythonでのPDF処理・自動化を動画で学ぶなら
Pythonの自動化を基礎から動画で学びたい方には、オンライン学習サイト「Udemy」が選択肢です。自分も書籍だけでは理解できなかった部分を、動画講座で手を動かしながら覚えました。買い切り型なので、セールのタイミングで気になる講座を試してみてください。
PDF構造解析の革命児pdfplumber
では、どのように構造解析を実装するのでしょうか。Pythonの世界には、強力な武器が揃っています。この難題を解決するためのライブラリが豊富です。
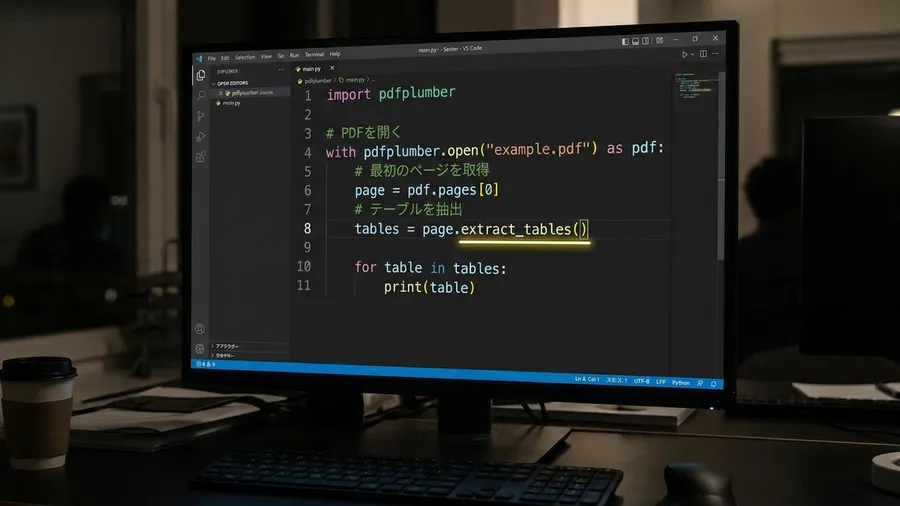
まず、基盤となる技術について説明します。pdfminer.sixというライブラリが重要です。これを使えば、内部要素をオブジェクトで取得できます。テキストや図形を、論理的な単位で扱えるのです。LTRectは四角形を、LTTextBoxはテキストの塊を示します。これらがどの階層にあるかを、ツリーで取得できます。これが、構造解析における最大の強みとなります。
しかし、これらを自力で計算するのは大変です。線とテキストの重なりを調べるのは骨が折れます。そこで、pdfplumberを活用しましょう。これは、pdfminerの機能を内部で呼び出しています。表の抽出に特化した、非常に使いやすい設計です。
PDF表抽出の救世主、pdfplumber
以前の私は、座標計算の泥沼にはまっていました。正規表現と計算を組み合わせて、苦労していました。特定の文字から何ピクセル移動するかを計算させます。三角関数を使うような、複雑なコードを書いていました。何百行ものスパゲッティコードが、努力の結晶でした。しかし、pdfplumberに出会って衝撃を受けました。その時の驚きは、今でも鮮明に覚えています。
たった数行のコードを走らせただけのことでした。複雑な請求書の表が、見事に抽出されたのです。二次元のリスト構造として、ターミナルに出ました。あまりのあっけなさに、思わず変な声が出ました。何日も抱えていた心の重荷が、消えていきました。その瞬間を、今でも明確に覚えています。
PDFテーブル抽出の簡単操作と高精度
コードの実装方針は、驚くほどシンプルになります。まずPDFファイルを読み込み、ページを指定します。あとは、テーブル抽出関数を呼び出すだけです。返ってきた配列から、必要なデータを取り出します。行と列のインデックスを指定するだけの手軽さです。
さらに、このライブラリは非常に優秀です。罫線がないレイアウトでも、対応が可能です。文字の揃え位置から、仮想的な表を作ることができます。これらの構造解析アプローチを、ぜひ駆使してください。定規で座標を測るような、不毛な時間は不要です。そのようなアナログな作業は、完全に過去のものになります。
変化に強い自動化を実現する構造解析
構造解析の考え方は、非常に重要です。Python以外の自動化でも、共通する設計思考です。
RPAツールを使って、ブラウザを操作する際も同じです。本質的な考え方は、PDF抽出と変わりません。画像認識や絶対座標に頼ったシナリオは、弱いです。解像度やウィンドウサイズの変化で、すぐに壊れます。そうではなく、UIの内部構造を取得すべきです。HTMLの要素や、コントロールIDを指定しましょう。変化に対する耐性を意識して、仕組みを作ってください。常に、堅牢なアクションを選ぶことが大切です。
PDF抽出 構造解析で保守ゼロ
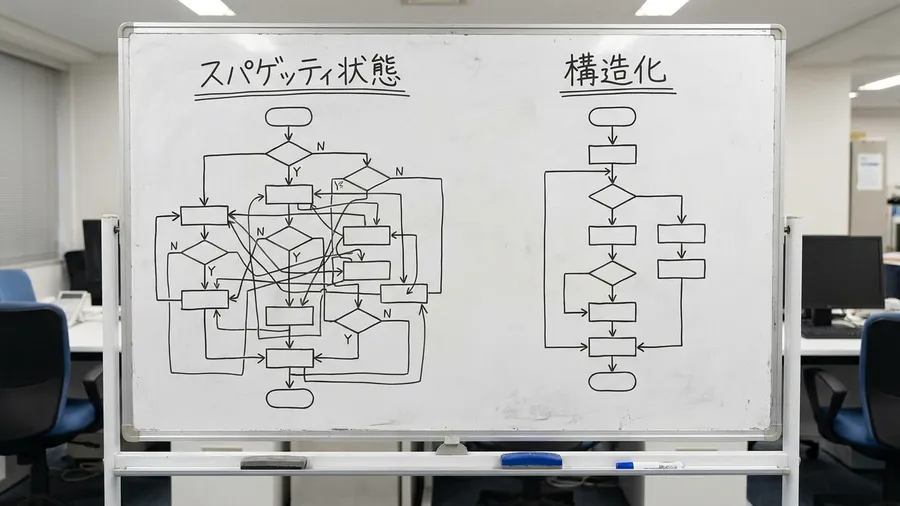
以前の私は、取引先ごとにスクリプトを量産しました。数十種類の座標指定コードを作るのは、失敗でした。取引先が増えるたび、分岐処理が増えていきました。条件分岐が20個を超える、巨大なプログラムです。まさに、モンスターのようなコードになっていました。
月末になるたび、どこかのフォーマットが変わりました。その都度、コードの修正作業に追われていました。毎月10時間以上を、保守作業に奪われていたのです。しかし、構造解析ベースの手法に変えてから一変しました。事態は、劇的に好転したのです。
表の構造さえ認識できれば、あとは簡単です。キーワードを配列内から検索するだけで済みます。「合計」の隣にある要素を、取得するだけです。レイアウトがずれても、この論理ルールは壊れません。共通のロジックで、ほとんどの会社に対応できました。メンテナンスの時間は、実質的にゼロになったのです。
データとしてのPDF
PDF抽出における課題と解決策を、解説してきました。結論は、極めてシンプルなものです。
PDFを「絵」として見るのは、今日でやめましょう。裏側にある「データ」として扱うべきです。物理的な点への依存は、常に崩壊のリスクがあります。1ミリのズレでエラーが起きる仕組みは、脆いです。そのような仕組みを使い続けるのは、苦痛でしかありません。
構造解析ライブラリという武器を、手に入れてください。そうすれば、レイアウトの揺れに振り回されません。論理的な要素の連なりとして、文書を読み解きましょう。強固な構造から、確実にデータを引き抜くのです。このアプローチにより、処理への恐怖は自信に変わります。深夜のコード修正という日々も、終わりを迎えます。
自動化の目的:創造性向上と雑務からの解放
自動化とは、単なる置き換えではありません。些細な変化を、プログラム自身に吸収させることです。人間が気にする必要のない部分は、任せましょう。そして、私たちは本来の創造的な仕事に集中します。そのような時間を作り出すことが、真の目的です。
表ズレの恐怖から逃れるには、視点を変えましょう。堅牢な抽出ロジックを、今すぐ取り入れてください。終わりの見えないデータ修正から、抜け出しましょう。それが、快適な自動化への第一歩となります。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
関連書籍
PDF処理やPython自動化を、手元で見返せる形で整理したい場合
pdfplumberやPythonの自動化は、作りながら調べ直す場面が多いです。詰まったときに参照できる本を1冊置いておくと、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。