
請求書PDF、手入力の悪夢
時刻は午後3時を回っていました。薄暗い蛍光灯の下、私は経理部門のデスクに座り、途方に暮れていました。パソコンの画面には、取引先から届いた大量のZIPファイルが表示されています。ファイルを一つずつ解凍すると、100件を超える請求書PDFがフォルダの中に溢れかえりました。そのとき、上司から「今日の夕方までにExcelにまとめておいて」と何気なく言われました。そのたった一言によって、私の定時退社の希望は完全に幻となりました。
崩れ去るExcelシートの絶望

最初は、簡単なコピペ作業で済むだろうと楽観視していました。まずPDFファイルをダブルクリックして開きます。次に該当箇所をマウスで慎重にドラッグしました。CtrlキーとCキーを同時に押して、内容をコピーします。そして隣の画面で開いたExcelシートに貼り付けました。しかし、貼り付けられたデータを見て絶望しました。「株式会社」と社名の間に、謎の改行が入っています。金額を示すカンマも、どこかへ消え去っていました。さらに、複数列に分かれていた数字が1つのセルに詰め込まれています。何度やり直しても結果は同じでした。レイアウトが崩れ去ったExcelシートを前に、強い焦燥感を感じました。「結局、手で一文字ずつ打ったほうが早いのではないか」という現実に直面しました。
手作業入力の苦痛
まず、デュアルモニターをフル活用することにしました。片方にPDF、もう片方にExcelを全画面で配置します。AltキーとTabキーで頻繁に画面を切り替えました。請求金額や日付、取引先名をひたすら手作業で打ち込み始めます。1件あたりの作業時間は約3分ほどかかります。もし100件あれば、合計で300分が必要です。つまり、丸5時間もの時間がこの単純作業だけで消えてしまう計算です。人間が作業する以上、どうしても入力ミスは避けられません。そのため、入力後のダブルチェックも決して欠かせない工程となります。私の穏やかな午後の時間は、完全に消滅しました。肩の筋肉は石のように凝り固まっていきます。ドライアイの影響で、モニターを見つめる目もひどく霞んできました。「こんな作業は、人間がやるべきことではないはずだ」。そんな苦しい思いを抱えながら、私は無心でキーボードを叩き続けていました。
PDFの構造が生む不便さ
なぜPDFという形式は、これほどまでに融通が利かないのでしょうか。悩みながら原因を調べていくうちに、PDFが持つ根本的な思想にたどり着きました。PDFの正式名称は「Portable Document Format」といいます。どんなOSやプリンター環境でファイルを開いても、文字の位置が保たれることを目的としています。レイアウトが「紙に印刷したときと全く同じように」再現されることが、この規格の至上命題なのです。しかし、この非常に強固な仕様こそが、データ抽出における最大の障壁となります。
PDFの描画命令という壁
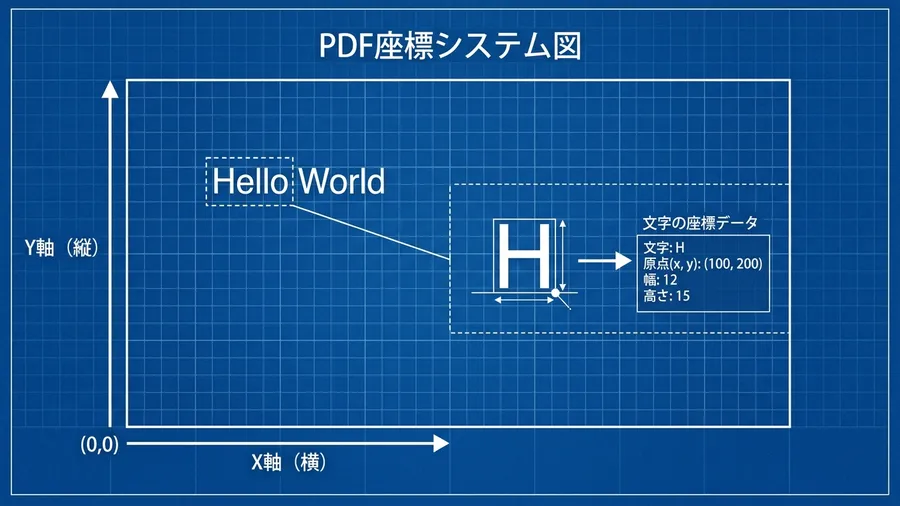
PDFの内部データは、WordやExcelとは全く異なる仕組みをしています。「ここは表の1行目である」といった論理的な構造を一切持っていません。また、「ここは段落の始まりである」といった情報も存在しません。内部には、「X軸が150、Y軸が200の場所に、特定のフォントで文字を描画せよ」という命令が並んでいます。このような座標指定の命令が、ただ羅列されているだけなのです。画面上で人間が「美しい表」として認識しているものは、実体ではありません。単に直線と文字列が、絶妙な座標で組み合わさっているだけの「絵」にすぎないのです。
PDFコピペの現実:データ構造の溝
そのため、マウスで文字の塊をドラッグしても、PDF側は意図を汲み取ってくれません。「表のデータをコピーされた」とは、決して認識してくれないのです。指定された範囲にある文字列を、論理的な順序も無視してコピーします。そしてクリップボードへ無造作に放り込むだけなのです。この「目に見える文字」と「実際のデータの構造」の間には、深い溝がありました。その事実を理解したとき、PDFに対する焦燥感は諦めへと変わりました。PDFとは、そもそもそういう仕組みのものなのです。気合いや根性でコピペを頑張ったところで、根本的な解決には至りません。ソフトウェアの構造という物理法則には、どうしても抗えないことを痛感しました。
pdfplumberの魔法、PDF表を完全抽出
絶望の淵にいた私を救い出したのは、Pythonというプログラミング言語でした。さらに「pdfplumber」というライブラリの存在が大きな力となりました。PythonでPDFを読み取るためのライブラリは、無数に存在します。最初は、定番とされる「PyPDF2」というツールを試してみました。しかし、結果は期待通りにはいきませんでした。テキストを抽出できても、空白が無視されて単語同士がくっついてしまいます。また、表の中身が単なるテキストの羅列になってしまいました。手作業のコピペと、なんら変わらない出力しか得られなかったのです。「やはりPDFの自動化は不可能なのか」と諦めかけました。そんなとき、海外の技術フォーラムでpdfplumberの存在を初めて知ったのです。
表構造を認識するextract_tableメソッド
このライブラリが持つ最大の特徴は、解析の細かさにあります。PDF内にある文字や線の「座標情報」を、徹底的に解析してくれる点です。そして何より衝撃的だったのが、「.extract_table()」というメソッドの機能でした。この関数は、PDFのページ内にある「直線」の交差を自動で見つけてくれます。さらに文字の配置間隔を計算し、表の構造を正しく導き出します。「人間が見ているのと同じように」表を認識してくれるのです。
PDFデータ化の魔法
さっそく、VSCodeの編集画面を開きました。わずか数行のコードを慎重に書き込んでいきます。PDFのファイルパスを正しく指定して、このメソッドを実行してみました。Enterキーを力強く叩いた瞬間、ターミナル上に変化が起きました。そこには、非常に美しい二次元のリストが吐き出されていました。セルごとのデータが、きれいにカンマで区切られています。行ごとに正しく改行も行われていました。手作業で必死に修正していた、あの「コピペの崩れ」が一切ありません。PDFの堅い装甲が透明になったような感覚でした。その奥にある純粋なデータだけを、一瞬で抽出できたのです。「これです。これでようやく家に帰れる」。薄暗いオフィスの中で、私は一人、静かに胸を撫で下ろしました。自動化の魔法は、確かに目の前に存在していました。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
クロップ機能で請求書抽出
表データを取得できるだけでも、実務においては革命的な進歩でした。しかし、実際の請求書はそれほど単純な作りではありません。多くの請求書において、重要な項目は表の外に配置されています。たとえば「取引先名」や「請求金額の合計」などが該当します。これらは、右上の余白にぽつんと印字されていることが多いです。あるいは、表の真下に大きなフォントで書かれていることもあります。これらをどうやって正確に取得すればよいのでしょうか。ここで大きな力を発揮したのが、pdfplumberの「クロップ機能」です。
座標の枠による精密な抽出
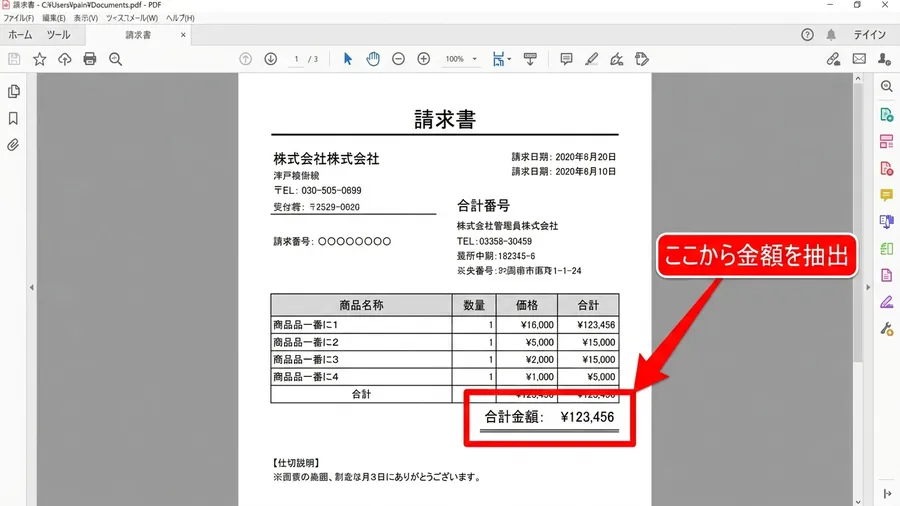
クロップとは、文字通りPDFのページを特定のサイズで「切り抜く」機能のことです。ページ全体からテキストを探す必要はありません。「左端から300ポイント、上から50ポイントの位置」というように指定します。そこから始まる四角形の範囲、つまり「座標の枠(Bounding Box)」を定義します。そして、その枠の内部に存在するテキストだけを、狙い撃ちで抽出するのです。
座標調整の試行錯誤、自動抽出の確信
そのため、最初は適切な座標を見つける作業に少し苦戦しました。指定した枠が小さすぎると、金額の最後の「円」という文字が切れてしまいます。逆に枠が大きすぎると、隣にある「発行日」の文字まで混入しました。プログラムを実行してはエラーの内容を確認します。数値を数ポイントずつ微調整する、地道なトライアンドエラーの繰り返しでした。しかし、この手間が必要なのは最初の一回だけです。同じフォーマットの請求書であれば、一度完璧な座標を見つければ十分です。あとはプログラムが、永遠に同じ場所を正確に読み取り続けてくれます。
不要な文字のクリーニング処理
抽出した文字列に対して、さらなる処理を加えていきます。Pythonの文字列操作機能を使い、不要な空白などを取り除きました。宛名に含まれる「様」という文字を消去する処理も記述します。ターミナルに「株式会社〇〇」と「500000」という、きれいなデータが出力されました。その結果を見たとき、私は確信しました。このスクリプトさえあれば、どんなに複雑なPDFでも自動化できるはずです。
大量PDFをPythonで自動Excel化
1枚のPDFから情報を抜き出す手法は確立できました。しかし、現場での本当の課題は「大量のファイルをどう処理するか」にあります。毎月送られてくるPDFの数は、100枚を優に超えます。これを1ファイルずつ手動でプログラムに渡すわけにはいきません。それでは自動化の価値が半減してしまいます。そこで、Pythonの標準ライブラリである「glob」を活用することにしました。
globによるファイルの一括取得
globは、フォルダ内にある特定の条件に合うファイルを、一網打尽に集めてくれます。非常に強力で便利なモジュールです。特定の拡張子を検索するコードを1行書くだけで準備は完了します。フォルダ内のすべてのPDFファイルのパスが、瞬時にリスト化されました。あとは、for文を使ってこのリストを順番にループさせるだけです。まず、1枚目のPDFを開きます。次に取引先名と合計金額を、クロップ機能で精密に抜き出しました。続いて表の中から、特定の明細行をメソッドで取り出します。それらのデータを辞書型にまとめて、配列の中に格納していきました。この一連の作業を、100回連続で自動的に繰り返すのです。
Excel出力の自動化と劇的時短
そして、いよいよ最終段階に入ります。抽出したデータが詰まった配列を、データ分析ライブラリ「pandas」へと渡しました。このデータをpandasのDataFrameという形式に変換します。すると、「to_excel()」というメソッドを1回使うだけで済みます。瞬時に、すべてのデータがExcelファイルとして書き出されるのです。ついに全ての準備が整いました。100枚のPDFが入ったフォルダを用意し、スクリプトを実行させます。ターミナルには、処理が終わったファイル名が次々と流れていきました。わずか10秒後、フォルダの中に「まとめデータ.xlsx」が生成されました。
5時間の作業が10秒で完了
ファイルをダブルクリックして中身を確認しました。そこには、非常に美しい表が完成していました。100社分の取引先名や日付、金額が並んでいます。1セルのズレもなく、完璧に整然とした状態で保存されていました。これまで5時間かかっていた手作業が、たった10秒の待ち時間に変わりました。全身に鳥肌が立つほどの、大きな達成感を感じた瞬間でした。
重労働からの解放、本質業務へ
さらに、この自動化スクリプトが完成してからというもの、私の仕事は劇的に変わりました。以前は月末月初になるたびに、憂鬱な気分になっていたものです。目の前に積み上げられたPDFの山を見て、ため息をついていました。単純作業の遅れは、心に焦りを生み出します。焦りはミスを誘発し、さらに残業が増えるという負の連鎖に陥っていました。今では、届いたZIPファイルを解凍して、フォルダに放り込むだけです。あとはPythonのスクリプトを実行するだけで作業は終わります。コーヒーを淹れて一息ついている間に、すべての転記作業が完了しています。
精神的な余裕が生む付加価値

手入力の苦しみから解放されたことで、大きなメリットを得られました。それは単に「時間に余裕ができた」ことだけではありません。最も価値があるのは、精神的な余裕が生まれたことです。空いた時間を使い、より高度な業務に取り組めるようになりました。たとえば、抽出したExcelデータを基にした「経費の月次推移の分析」です。また、金額に間違いがないかを確認する「異常値のチェック」も行えます。これらは、人間本来の役割である「考える仕事」といえます。データの転記は、あくまで業務の準備段階にすぎません。その準備作業に貴重な時間をすり減らすのは、非常にもったいないことだと今は感じています。
PDF重労働からの解放、Python
もしあなたが今、大量のPDFを前にして途方に暮れているなら、ぜひこの方法を試してください。コピペと手入力の無限ループに疲れ果てている方にも、心からお勧めします。Pythonとpdfplumberの世界に、一度触れてみてください。プログラミングの経験が全くなくても、心配する必要はありません。もしエラーが出たとしても、AIが解決策を即座に教えてくれる時代です。重労働から自分自身を解放しましょう。そして、あなたが本来やるべき大切な仕事に時間を使ってください。そのための強力な武器は、確実にそこに用意されています。
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
私自身も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
関連書籍
Python業務自動化関連書籍を、手元で見返せる形にしておきたい場合
Pythonやデータ処理の自動化は、作りながら同じ基礎を何度も確認する場面が多いです。手元で見返せる本があると、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。