
見た目同じ値なのに#N/A
月末のオフィスでの出来事です。周囲の社員は、次々と帰宅していきます。フロアには、キーボードを叩く音だけが響いていました。手元には、売上データがあります。別システムからは、顧客マスターをダウンロードしました。これらを社員番号や顧客IDで、結合したいだけでした。いつものように、VLOOKUP関数を入力します。そして、数式をコピーしたときのことです。画面をスクロールしてみました。すると、胃の奥が重くなるような光景が広がっています。無情な「#N/A」の文字が並んでいました。それは、そこかしこに存在していたのです。
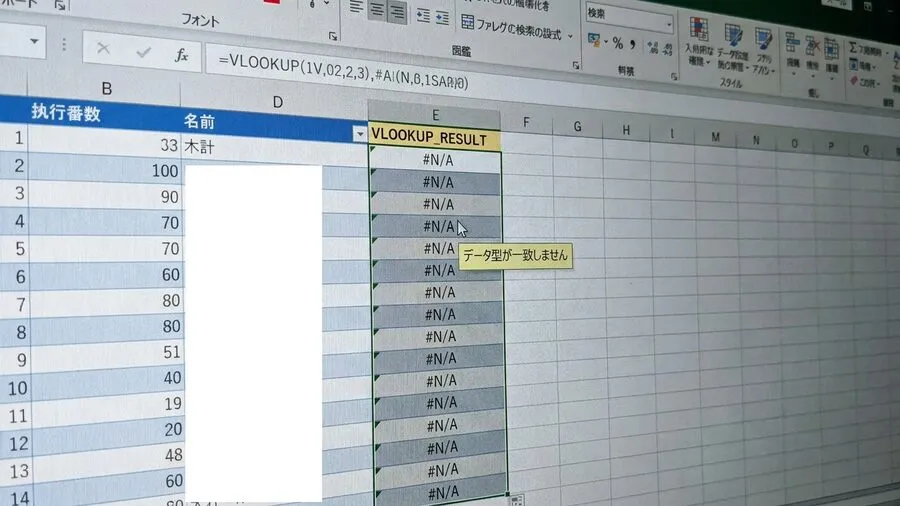
引数の設定には、間違いありませんでした。検索値のセル番地も、正しいものでした。範囲指定の絶対参照も確認しました。ドルマークも、しっかり付けてあります。該当のセルを、一つひとつ確認してみました。売上データ側は「10054」となっています。顧客マスター側も「10054」でした。どこから見ても、同じ値にしか見えません。半角スペースが混ざっているのかと疑いました。TRIM関数を使ってみましたが、結果は変わりません。
LEN関数で文字数を数えてみました。どちらも、きっちりと5文字です。それなのに、Excelは別の判断をしました。「この2つは全くの別物ですよ」と言っています。Excelは冷たく、エラーを出し続けていました。まるで魔法が、解けてしまったかのようです。Excelの機嫌を、損ねてしまったのでしょうか。このような不可解な挙動には、困惑します。本当に、途方に暮れてしまいますよね。
謎のエラーで終電を逃した夜
部署異動して、間もない頃の話です。初めて、この原因不明のエラーに遭遇しました。そのときは、文字通りパニックになりました。上司からは「まだ終わらないの?」と急かされます。焦りで、手汗をかきながら作業しました。一つひとつのセルを、ダブルクリックします。そして、目視での確認を繰り返しました。
結局、原因はわかりませんでした。最後は、手作業でコピペを繰り返しました。終電の間際まで帰れなかった、苦い思い出です。見えない何かに、邪魔をされているようでした。この不可解な現象のせいです。本来なら、数分で終わるはずの処理でした。それに何時間も、奪われてしまったのです。あの時の絶望感と疲労は、今も忘れません。私は「Excelのエラー」を警戒するようになりました。得体の知れない相手だと、感じるようになったのです。
VLOOKUPを阻むデータ型不一致の罠
この現象の正体について、お話しします。それは、データの「型」の違いです。人間にとっては、どちらも同じ「100」です。しかし、コンピューターの内部は違います。「計算できる数値の100」があります。一方で「文字としての100」もあります。この2つの状態は、明確に区別されています。VLOOKUP関数は、型まで一致を求めます。完全に一致しないと、マッチングしません。非常に厳格な仕様を持っているのですよ。
業務でよくあるケースを紹介します。基幹システムのCSVデータを使います。それを、手入力したExcelと突き合わせます。CSVデータは、文字列になりやすいです。これは、ゼロ落ちを防ぐための仕様です。一方、手入力は数値に変換されます。標準フォーマットによる自動変換が原因です。この「見えない境界線」が、作業を阻みます。普段は、この違いを意識しませんよね。だからこそ、多くの人が罠にハマるのです。
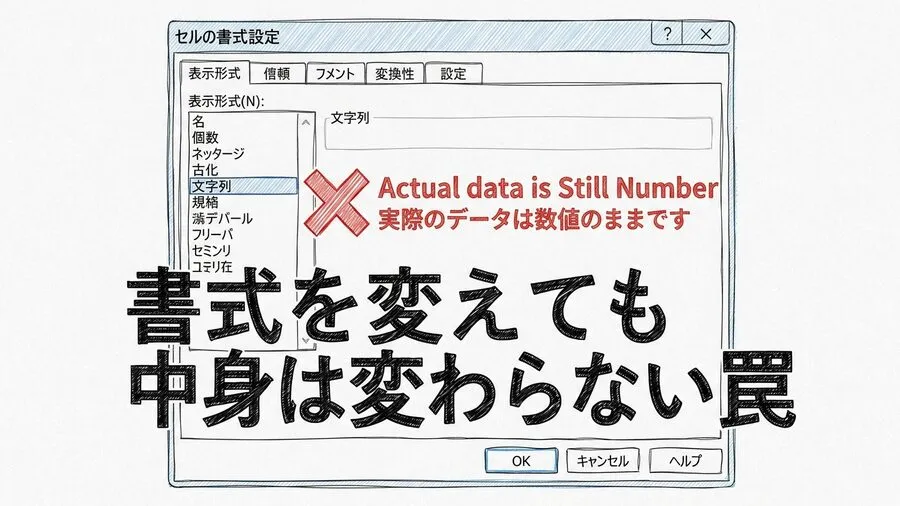
Excel表示形式の罠とVLOOKUPエラー
ここで、厄介な事実をお伝えします。Excelの表示形式を、変更したとします。セルを「文字列」に変えても、無駄なことがあります。中身が「数値」のまま、残るケースです。セルを選択して、設定を変えました。しかし、結果は#N/Aのまま変わりません。表示形式を変えただけでは、不十分です。内部の実体データまでは、変換されません。セルを編集状態にすれば、適用されます。これは、極めて気づきにくい罠と言えます。見た目は同じでも、内部の型が違います。これが、VLOOKUPエラーの最大の犯人です。直感に反する挙動には、驚かされますね。
Excelの型合わせ、人間の苦行
この状況を、打開しようと試みます。すると、必ず通る道があるのです。セルを選択して、F2キーを押します。そして、Enterキーを叩く動作です。すると、緑色の三角形の警告が出ます。「数値が文字列として保存されています」という内容です。これでようやく、文字列として認識されました。この一連の動作が、生産性を下げています。大きな要因のひとつと言えるでしょう。

理屈は、十分に理解できます。しかし、データが1万件ある場合はどうでしょう。手作業で繰り返すのは、かなりの苦行です。1件1秒としても、約2.7時間かかります。下矢印、F2、Enterを繰り返します。リズムよく動かすうちに、指がつりそうです。たまにリズムが狂い、入力を消してしまいます。このような失敗も、重なっていくのです。非生産的な時間は、避けたいものです。ビジネスにおいて、もったいないことです。私たちは、もっと建設的なことに時間を使うべきです。そう、思いませんか。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
人間に強いるデータ統一:業務フローの欠陥
以前、大量の顧客リストを扱いました。10万件のフォーマットを、統一する作業です。ひたすらF2とEnterを繰り返しました。結果、夕方には目が霞んでしまいました。頭痛薬を飲みながら、作業を続けました。Excelの「区切り位置」機能も、一応あります。しかし、それを毎回行う必要があります。その時点で、業務フローには欠陥があります。人間が型に気を遣うのは、不自然です。結合前にお膳立てをするのは、疲れます。本来あるべき姿ではないと、感じます。私たちが注力すべきは、分析や意思決定です。データクレンジングに、時間を奪われてはいけません。貴重な思考の時間が、あまりにももったいないです。
Python pandasによるデータ結合の型統一
Excelの機能だけでは、限界があります。どうしても、手作業が残ってしまいます。そこで、真価を発揮するのがPythonです。データ分析用のpandasを使いましょう。不毛な型合わせを、一瞬で終わらせます。データの読み込みから、変換まで自動です。結合までを全自動で行う、強力な機能です。一度、自動化を体験してみてください。もうExcelの手作業には、戻れません。それほどの快適さを、感じられるはずです。自動化されたフローは、魔法のような快感です。
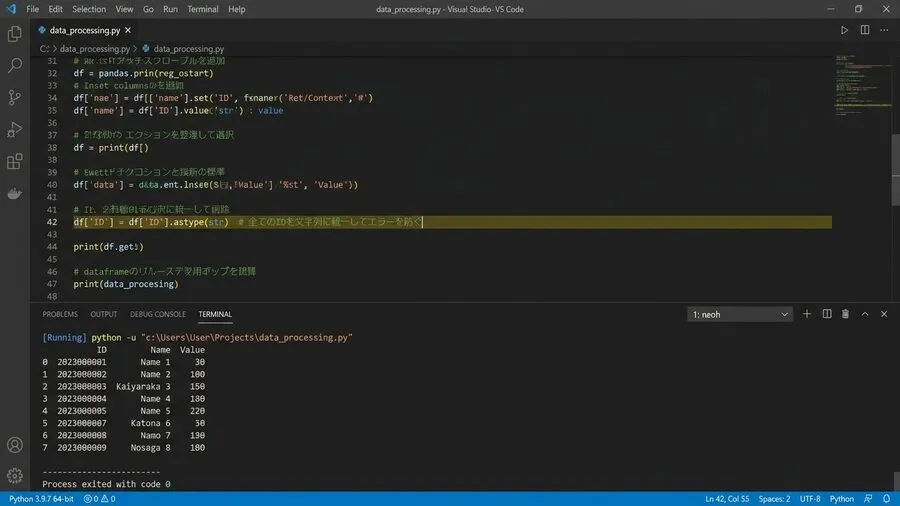
ただし、pandasにも注意点があります。読み込み時に、型が混在する場合です。すると「object型」として処理されます。これでは、結合時にマッチングしません。しかし、スクリプトで変換すれば解決です。10万件のデータも、約0.5秒で終わります。人間が数時間かけていた、あの作業です。コンピューターには、一瞬の時間なのです。このギャップを知ることは、重要です。エンジニアリングの世界への、第一歩となります。非常に重要なステップだと、言えるでしょう。
強制型統一によるエラー根絶
対処法は、非常にシンプルです。結合キーとなる列を、上書きしましょう。強制的に、すべて同じ型にするのです。有無を言わさず、「文字列」に揃えます。単一の型にしてから、突き合わせます。これが、エラーを根絶する最強の方法です。迷いを生ませない、強力なアプローチです。データ処理における、基本原則と言えます。複雑な関数を、組み合わせる必要はありません。データ自体を整えるほうが、はるかに堅牢です。確実なシステムを、構築できるのです。
astype(str)で結合キー統一
具体的な方法について、説明します。pandasの「astype(str)」を使います。これは、型を変換するメソッドです。
コードは、わずか1行で済みます。該当の列を、文字列に変換する指定です。これにより、数値であっても文字列になります。すべて例外なく、文字列として扱われます。顧客マスター側にも、同じ処理を行います。その後に、pandas.mergeを実行してください。これで、作業はすべて完了となります。この1行だけで、エラーが消え去ります。今まで悩んでいたのが、嘘のようですよね。技術の力を使えば、簡単に解決できます。思わず声が出てしまうほど、驚くはずです。
VLOOKUP不要!Pandas Mergeと型合わせ
結合キーの両方に、この処理を適用します。見えない型の不一致は、解消されます。私が初めて、これを実行した時の話です。一瞬で処理が終わり、驚きました。すべてのデータが、正しく結合されています。いままでの苦労は、何だったのでしょうか。驚くと同時に、非常に感動しました。データの入り口で、型を強制的に合わせます。この定型文を、用意しておきましょう。データソースの状態は、問いません。確実にマッチングを、成功させられます。VLOOKUP特有の、あのエラーはありません。そこから解放されるのは、大きな進歩です。
「見た目同じなのに結合不可」問題の解決へ
「見た目が同じなのに結合できない」問題です。このExcelの仕様は、厄介な存在でした。多くの人の時間を、奪ってきたのです。その度に、人間が対応しては疲弊します。それは、非効率の極みと言えます。システムが勝手に解釈を、変えてしまうのです。ならば、私たちが主導権を取り戻しましょう。

一括処理を、導入してみてください。目視確認のストレスは、劇的に減ります。エラーが出る不安も、感じる必要はありません。型を揃える前処理を、自動化しましょう。それだけで、業務はより安定します。明日からのデータ集計が、変わります。少しでも、穏やかなものになるよう願います。テクノロジーを、味方につけてください。私たちの仕事は、もっと自由になれます。創造的なことに、時間を使えるはずです。作業を制御できているという、実感を得られます。それは、自分の自信にも、つながります。
関連リンクとチェックリスト
データ型不一致は、Excelだけの話ではありません。プログラミングを学ぶ過程で、知りました。データベースでも、型は非常に重要です。Excelでの苦労が、ここで生きました。プログラミング学習中に、気づいたのです。「これは、あの時のVLOOKUPと同じだ!」と。腑に落ちた瞬間は、小さな感動でした。あの時の苦労が、習得を助けてくれています。Excelだけで、諦めなくてよかったです。今の私があるのは、あの経験のおかげです。
VLOOKUPのエラーに、悩んだ日々がありました。私にとっては、それが入り口でした。プログラミングの世界への、第一歩です。Excelでは、解決できない壁がありました。その時、Pythonというツールに出会ったのです。実際に学んでみて、衝撃を受けました。数時間の作業が、一瞬で終わるからです。あの頃の自分に、教えてあげたいです。今、同じ壁にいる方にも、伝えたいです。ぜひ、同じ感動を味わってほしいと願います。
今では、エラーが出てもパニックになりません。「型が違うのかもしれない」と分析します。冷静に、状況を判断できるようになりました。Pythonで解決するという、選択肢もあります。これは、仕事への向き合い方の変化です。問題解決の姿勢が、大きく変わりました。
関連書籍
Python業務自動化関連書籍を、手元で見返せる形にしておきたい場合
Pythonやデータ処理の自動化は、作りながら同じ基礎を何度も確認する場面が多いです。手元で見返せる本があると、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)