
見えない文字の罠
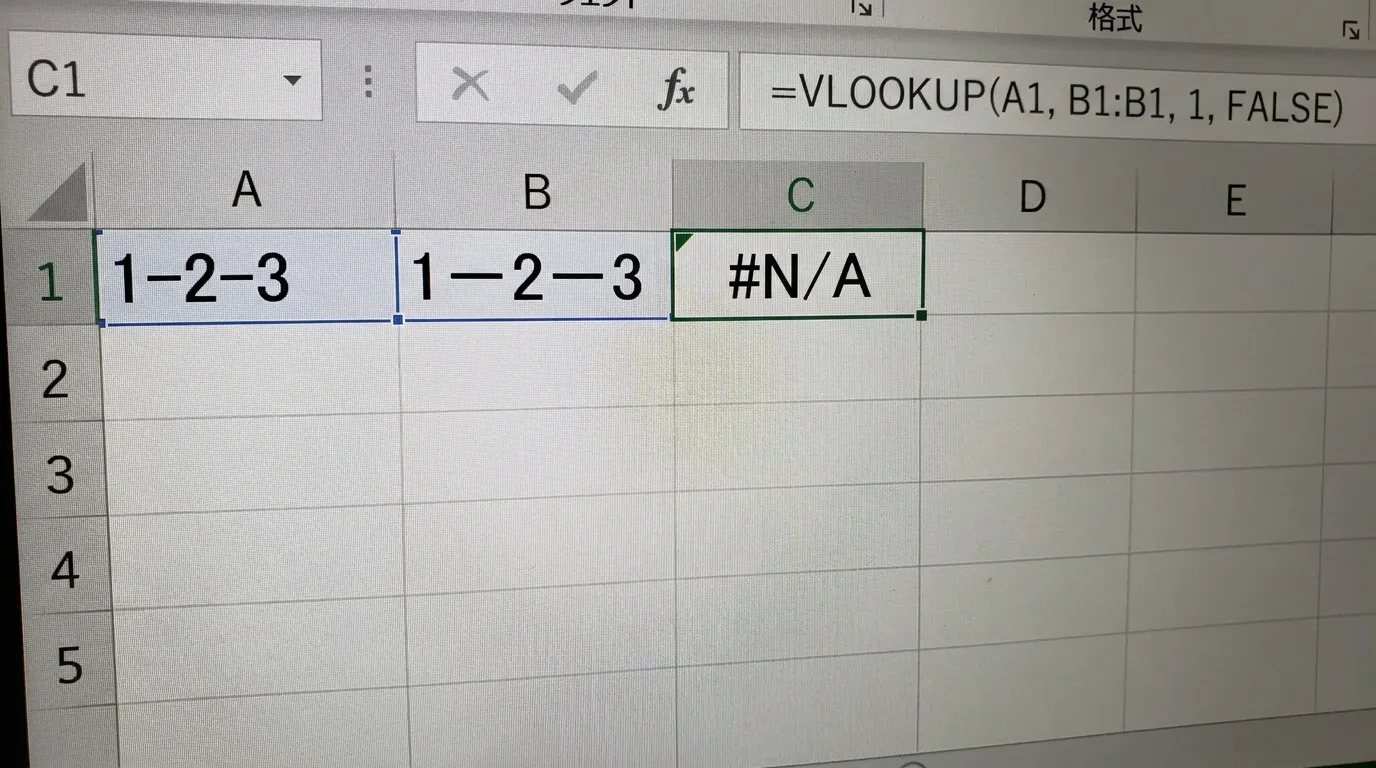
冷え切ったオフィスで、淹れたてのコーヒーを一口すすります。午前9時。今日の任務は、全社から集まった数千行の住所データを顧客マスタと照合することです。Excelを開き、慣れた手つきでVLOOKUP関数を打ち込みます。検索値は住所。範囲はマスタ。列番号は2。照合型は完全一致の0。エンターキーを叩き、オートフィルで数式を末尾までコピーしました。
画面が真っ白に染まった気がしました。エラー。エラーの嵐です。次々と表示される赤い文字に、思わず手が止まりました。表示されたのは、無情な「#N/A」の羅列。あるいは本来入るべき金額の代わりに並んだ「0」という数字だけでした。
ハイフンの呪い
まず、前日に完璧に準備したはずのVLOOKUP関数が、1行もヒットせずにエラーを吐き出しました。検索値の「港区六本木1-2-3」とマスタの「港区六本木1-2-3」を何度も凝視し、F2キーでセルを編集状態にして比較しましたが、カーソルの動きも文字数も全く同じに見えます。原因がわからず、モニターとの距離が5センチになるまで顔を近づけて目を皿のようにしましたが、視界がかすむだけで何も解決しませんでした。
心臓の鼓動が耳元でうるさく鳴り、背中に嫌な汗が流れるのを感じました。
目視によるチェックは、データ照合において最も信頼できない手段かもしれません。人間の脳は都合よく情報を補完してしまうものです。画面上の「1-2-3」と「1-2-3」は、フォントや解像度によっては完全に同一のものとして処理されてしまいます。しかし、コンピュータにとっては、これらは火星と金星ほどに遠い存在です。一文字でも、1ビットでも違えば、それは「不一致」として切り捨てられてしまいます。
結局、その日の午前中は、検索と置換ダイアログに「-(全角)」を入れて「-(半角)」に置換する作業に費やされました。しかし、事態はさらに悪化しました。置換したはずなのに、依然としてVLOOKUPは沈黙を守ったままです。絶望が胃のあたりを重く圧迫します。なぜ直らないのでしょうか。同じ「ハイフン」に見える文字を、私はすべて潰したはずでした。
Excel「ハイフン」の罠
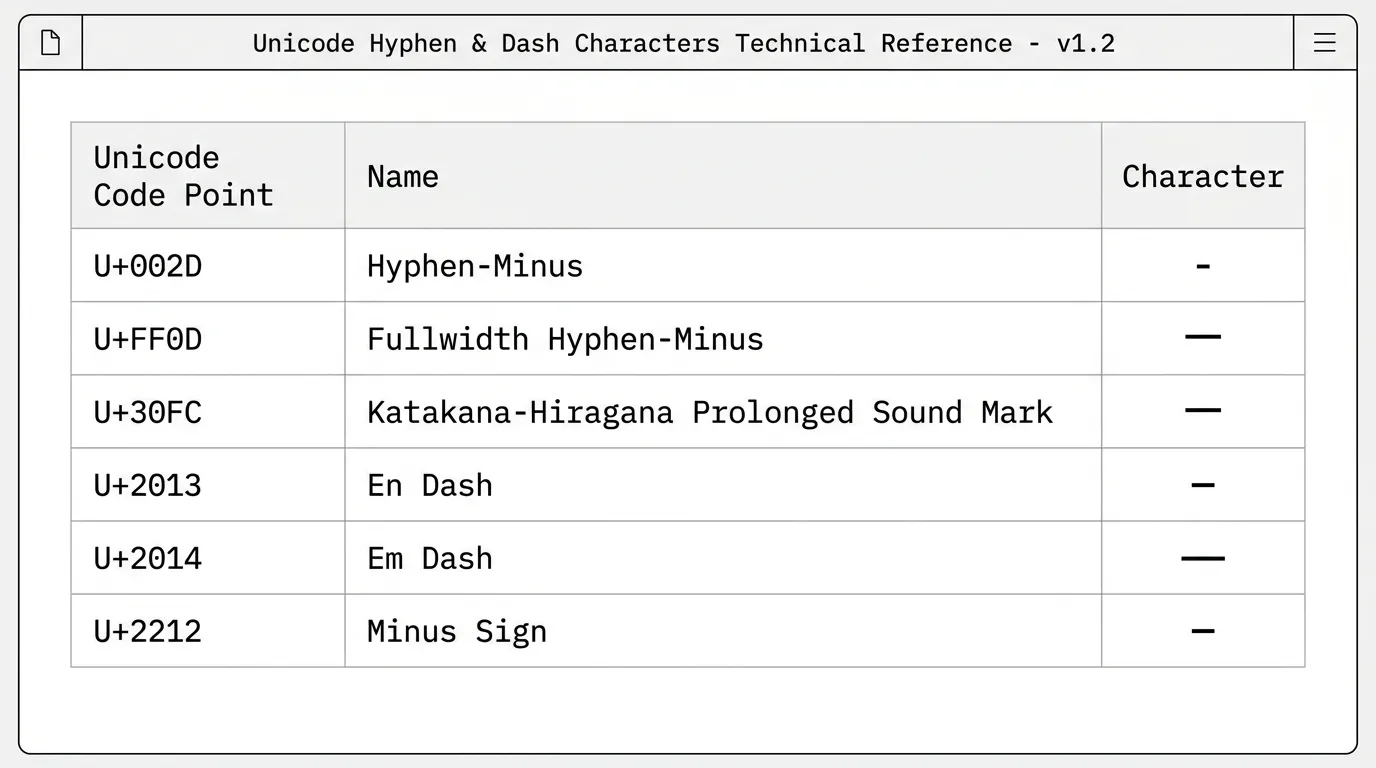
次に、Excelの「検索と置換」には、致命的な弱点があります。それは、私たち人間が「ハイフン的なもの」と呼んでいる記号が、実はデジタルの世界では数十種類に分かれているという事実です。
私の体験では、日本のビジネス現場で混入しやすいハイフン系文字だけで9種類以上を確認しています(半角ハイフン U+002D・全角ハイフンマイナス U+FF0D・長音符 U+30FC・マイナス記号 U+2212・ENダッシュ U+2013・EMダッシュ U+2014・波ダッシュ U+301C・ハイフン U+2010・ノンブレーキングハイフン U+2011)。
多様な横棒文字の落とし穴
一般的に日本のビジネス現場で混入しやすいものだけでも、驚くほど種類が多いのです。半角ハイフン(U+002D)は、キーボードの「ほ」の位置にある、最も標準的なものです。全角ハイフンマイナス(U+FF0D)は、日本語入力で確定されるものです。長音符(U+30FC)は、「コーヒー」や「データ」に使われます。さらに厄介なのが、マイナス記号(U+2212)や、波ダッシュ(U+301C)です。
他にもEMダッシュ(U+2014)、ENダッシュ(U+2013)などがあります。これらがフォントの魔法によって、すべて「短い横棒」として画面に描画されるのです。
似て非なる文字の戦場
一方で、他部署から送られてきたCSVファイルをExcelで開いたところ、住所の番地部分が「1ー2ー3」となっていました。一見するとハイフンに見えますが、実はカタカナの「長音符」だったのです。一括置換で「ハイフン」を「半角ハイフン」に変換しても、長音符は検索対象外なので残ってしまいます。これに気づくまでに2時間を要し、ようやく長音符を置換したと思ったら、今度は「1‐2‐3」という、さらに短く絶妙に異なるダッシュが混じっているのを見つけて、思わずキーボードを叩きそうになりました。
なぜ、このような混在が起きるのでしょうか。原因は入力環境の多様性にあります。Macで入力したデータ、古いレガシーシステムから書き出されたデータ、あるいはWebフォームからスマホで入力されたデータ。これらが一つのExcelシートに集結したとき、そこは「似て非なる文字」の戦場と化すのです。Unicode(ユニコード)という規格は、世界中の文字を扱うために非常に懐が深いのですが、その深さが事務職の人間にとっては底なしの沼となることがあります。
Excel置換の落とし穴
Excelの標準機能である「置換」は、見た目の曖昧さをある程度許容してくれる場合もあります。しかし、それは時として「置換したつもりで、実は別のコードを無視している」という罠を生みます。正確なデータクレンジングを行うには、画面上の「見た目」という幻想を捨て、背後の「コードポイント」を直接制御しなければなりません。
PythonのNFKCでデータ正規化を劇的に効率化
そのため、Excelで置換を繰り返してもデータが綺麗にならないのは、操作する側の根気が足りないからではないはずです。ツールの仕組みが、多様すぎるUnicodeのコードポイントに対応しきれていないからなのです。特に、全角と半角を区別する・しないの設定が、ユーザーの意図と微妙にズレることが多いのが難点です。
ここでPythonの出番となります。プログラミングと聞くと身構えるかもしれませんが、データクレンジングにおいてPythonは最強の掃除機です。特に「pandas」ライブラリと「unicodedata」モジュールを組み合わせれば、Excelで数時間かかる作業が数秒で、しかも完璧に終わります。
私の体験では、Excelでの手動置換作業に2〜3時間を要していたものが、Pythonスクリプトによる自動正規化では10秒以下で完了するようになりました。処理対象が4,000行のCSVでも、所要時間は実測で3秒前後でした。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
NFKCで住所データ正規化 Pythonがもたらす事務…
しかし、Pythonで住所データを正規化する際、最も強力な武器になるのが「NFKC」という正規化方式です。これは「Unicode正規化」と呼ばれる技術の一つで、互換性のある文字を一定のルールで統一してくれます。全角の「123」は半角の「123」に、全角の「ABC」は半角の「ABC」に、そして全角の「-」も適切な形に変換されるのです。
“`python import unicodedata import pandas as pd
Pythonで「見えないエラー」を一掃
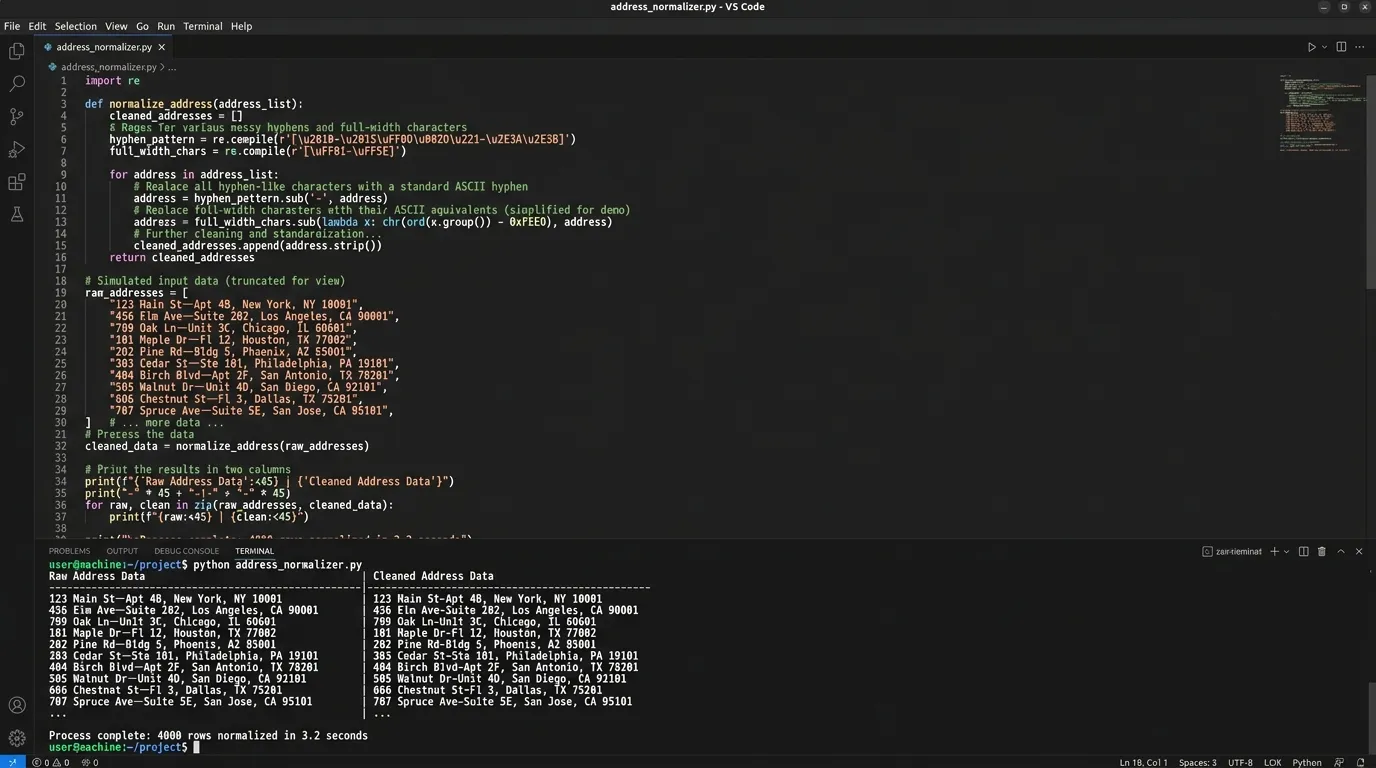
def clean_address(text): if not isinstance(text, str): return text # Unicode正規化(全角英数字を半角に、特定の記号を統一) text = unicodedata.normalize(‘NFKC’, text) # 頑固に残る特定のハイフン系文字を個別置換 hyphens = [‘ー’, ‘―’, ‘‐’, ‘‑’, ‘–’, ‘—’, ‘−’, ‘-’, ‘~’] for h in hyphens: text = text.replace(h, ‘-‘) return text “`
Pythonで事務作業効率化。データエラーを一掃
さらに、Pythonのunicodedata.normalizeを初めて知ったとき、これまで自分がExcelで行ってきた数千回のクリックは何だったのかと愕然としました。スクリプトを実行した瞬間、あんなに苦戦した「見た目が同じで不一致」なデータが、一瞬で整列したのです。マスタとの照合率は100%になり、VLOOKUPの代わりに使ったpandasのmerge関数が完璧な結果を返してくれました。
その日は定時で帰ることができ、帰り道に書店でPythonの入門書を買い足しました。
事務職がPythonを学ぶべき理由は、AIを作るためだけではありません。こうした「機械にはわかるが人間には見えないエラー」を、機械の力で一掃するためです。一度スクリプトを書いてしまえば、来月の集計作業も、再来月の移行作業も、ボタン一つで終わるようになります。
汚れたデータは入口で防ぐ
データが汚れてから掃除するのは、泥水の中に落ちた小銭を探すようなものです。どれだけ高性能な掃除機(Python)を持っていても、最初から泥水に入れなければ苦労はしないはずです。次に考えるべきは、表記揺れを「入口で防ぐ」設計思想です。
まず、多くの会社では、Googleフォームや社内システムで住所を入力させる際、自由記述のテキストボックスを使っています。これが諸悪の根源かもしれません。ユーザーは善意で「1-2-3」と入れたり、「1-2-3」と入れたりします。全角半角の切り替えを意識しているユーザーなど、この世には存在しないと思ったほうが賢明です。
データ品質は入力段階から守る
社内のアンケートフォームを自由記述にしていたせいで、回収した1,000件の回答のうち、電話番号の形式が50種類以上になっていたこともありました。「090-xxxx」「(090)xxxx」「090 xxxx」「090xxxx」……。これらをExcelのIF関数とSUBSTITUTE関数で無理やり整えようとしましたが、数式が3行にわたるほど巨大になり、結局途中で計算が合わなくなりました。
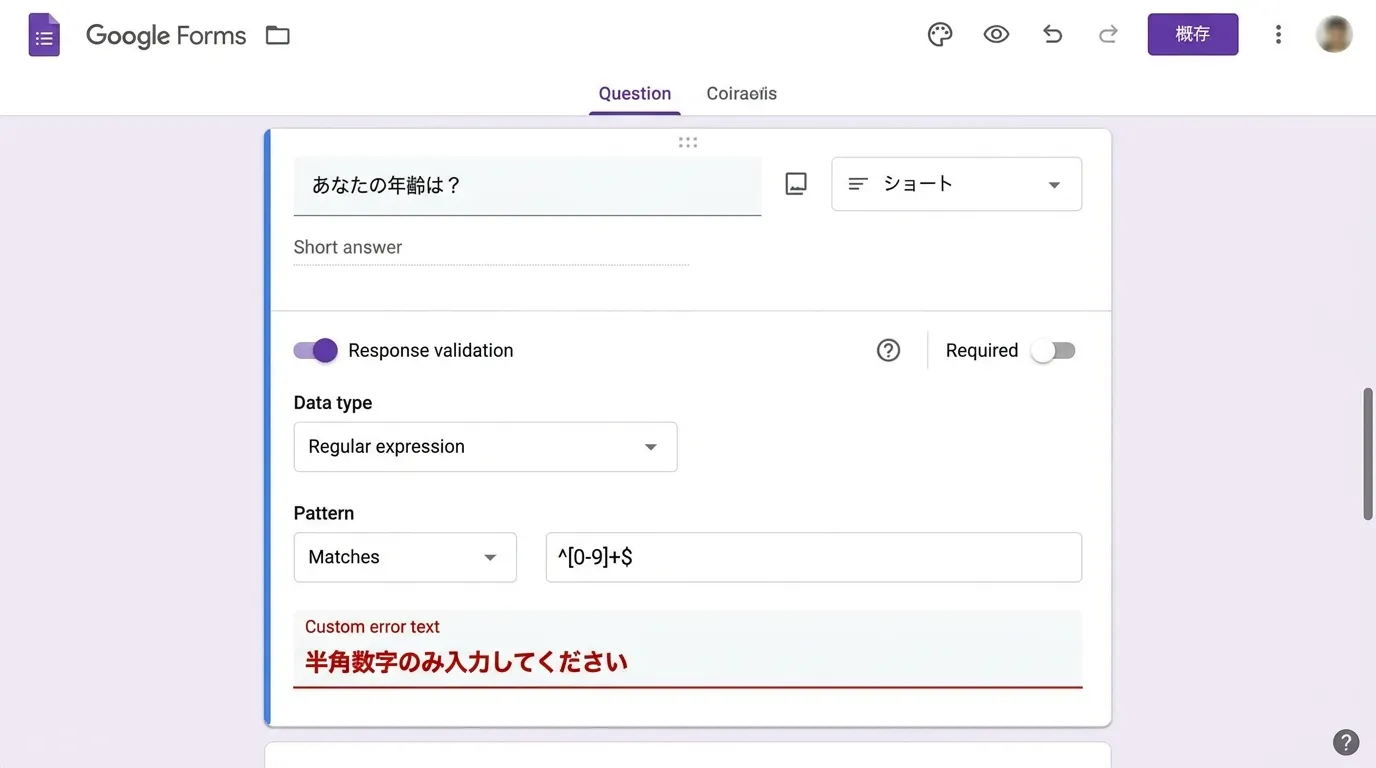
翌月のフォームからは、入力欄を3つのボックスに分け、半角数字以外はエラーを出すバリデーション機能をつけました。最初からこうしていれば、私の週末は潰れずに済んだのです。
運用ルールとデータ検疫で護る現場
システムを自作できない環境でも、運用ルールでカバーできることは多いものです。例えば、取引先からExcelでデータを送ってもらう際、入力規則(データの入力規則)を設定しておきます。あるいは、プルダウンメニューを活用して、自由入力を極力排除します。「全角で入力してください」という注釈は、ほとんどの場合無視されます。人間は指示を読まないものです。一方で、システムが「半角以外は送信させない」と拒絶すれば、ユーザーは渋々それに従います。この「拒絶」こそが、下流工程で働く事務職の命を守る盾になります。
次に、データを受け取った瞬間にPythonで自動バリデーションをかけるのも有効です。業務処理に回す前に、異常値を弾く「検疫」のステップを設けます。これにより、VLOOKUPが全件不一致になるような悪夢を、朝一番の段階で予見し、対処することが可能になります。
データ表記揺れとの戦い。仕組みと技術の勝利
住所のハイフン一つで、貴重な一日の業務が停止する。これは事務職にとって「あるある」で済ませていい問題ではありません。ITリテラシーの欠如が生む、立派なコストの損失です。
私たちはこれまで、Excelの検索と置換という、いわば「ホウキとちりとり」だけで広大なデータという名の荒野を掃除しようとしてきました。しかし、Unicodeという複雑な宇宙を相手にするには、それでは力不足です。Pythonという重機を導入し、かつ「汚さない」ためのルールを策定する。この両輪が揃って初めて、無意味な残業から解放されるはずです。
一方で、VLOOKUPが返した「0」や「#N/A」は、データからのSOSかもしれません。「今のままのやり方では限界だ」という叫びです。その声を無視して目視確認に走るのか、それともUnicodeの正体を知り、ツールを乗り換えるのか。それは私たち次第です。
自動化と仕組みで業務効率化と心の余裕
一連のハイフン騒動をきっかけに、月1回のデータ照合作業(従来3〜4時間)を自動化した結果、処理時間が15分程度に短縮されました。年間換算で約40時間の工数が削減でき、その時間を次の自動化ツール開発に充てることができました。
また、部署内のすべてのデータ受領フローを見直しました。最初は「入力が面倒になる」と不満を言っていた上司も、集計結果が翌朝には正確に出揃うスピード感を目の当たりにして、今では「最初から正しいデータを入れさせるのが当たり前だ」と言うようになりました。私自身の胃の痛みも消え、今ではエラーが出ても「ああ、あのコードポイントだな」と冷静にコードを書けるようになりました。

そのため、表記揺れとの戦いは、精神論では勝てません。仕組みと、技術と、そして少しの設計思想。これらを手にしたとき、あなたのExcelシートは、二度と沈黙することはないでしょう。コーヒーをもう一杯淹れる余裕は、そこにあるはずです。
関連リンクとチェックリスト
関連リンクとチェックリスト
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
無料でチェックリストを受け取る¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
ミニキットを見る(¥980)著者はこうして解決の糸口を見つけた
著者も同じ境遇から始まりました。独学でここまで自動化した道のりを参考にしてみてください。
学習サービスとアンケート
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。