
毎月のレポート作成が近づくたび、胃のあたりが少し重たくなっていました。複数部署のExcelファイルを開くと、「日付」という名前の列に全く別物のデータが並んでいたのです。あるファイルでは数字が8桁、別のファイルはスラッシュ区切り、時には謎の5桁の数字まで混じっていました。それらを一つの表にまとめる作業だけで、午前中の時間があっという間に消えていったのです。
手作業で一つずつ修正していた頃は、コピペとセル書式設定を繰り返すだけで疲弊していました。Pythonのpandasに出会ってから状況は少しずつ変わりましたが、日付の変換には独特の癖があります。何度もエラーに突き当たって頭を抱えながら、少しずつ解決策を見つけていきました。
この記事では、私が経験した日付フォーマットの混乱とpandasでの対処法を共有します。Excelの日付に振り回されている方の参考になれば幸いです。
バラバラ日付形式の悪夢
月次の売上集計業務には、大きな悩みの種がありました。それは、複数システムからダウンロードしたデータの日付形式です。驚くほどバラバラな状態でした。基幹システムから出力されるCSVを確認します。西暦が繋がった8桁の数字になっていました。一方で、現場の担当者が手入力してくる管理簿もあります。こちらはスラッシュ区切りの標準的な日付です。これらを一つのDataFrameに統合しようと試みました。毎回エラーとの戦いが始まったのです。
以前の私は、このバラバラな形式を整えるために必死でした。Excelの「区切り位置」機能を使ってみます。関数を駆使して力技で解決していました。しかし、データ量が数千行を超えてくると大変です。手作業自体がミスを誘発する温床になっていました。一箇所でも変換ミスがあれば、売上の計上月がずれてしまいます。上司への報告書が台無しになるでしょう。そんな不安を抱えながら、毎月30分以上の時間を費やします。
絶望の日付変換ミス
月曜の朝一番に提出すべきレポートでのことです。日付の変換ミスで、集計が一日ずれていると指摘されました。その瞬間の、頭から血が引くような冷たい感覚を覚えています。再び一からやり直す絶望感は今でも忘れられません。作業を急ぐあまり、見た目で判断した自分を何度も責めました。
カオスなExcel日付、自動化の壁
一つのExcelファイルの中を確認します。まるで別々の言語で書かれたような日付が同居していました。この光景は、まさにカオスそのものです。ある行には「20250115」という簡素な数字が並びます。すぐ下の行には「2025/1/15」という丁寧な表記がありました。さらに困ったことに、どこかのシステムを経由した影響でしょうか。「45292」という謎の5桁の数字まで混じっていました。これこそがExcel特有のシリアル値です。当時の私には何かのエラーコードにしか見えませんでした。
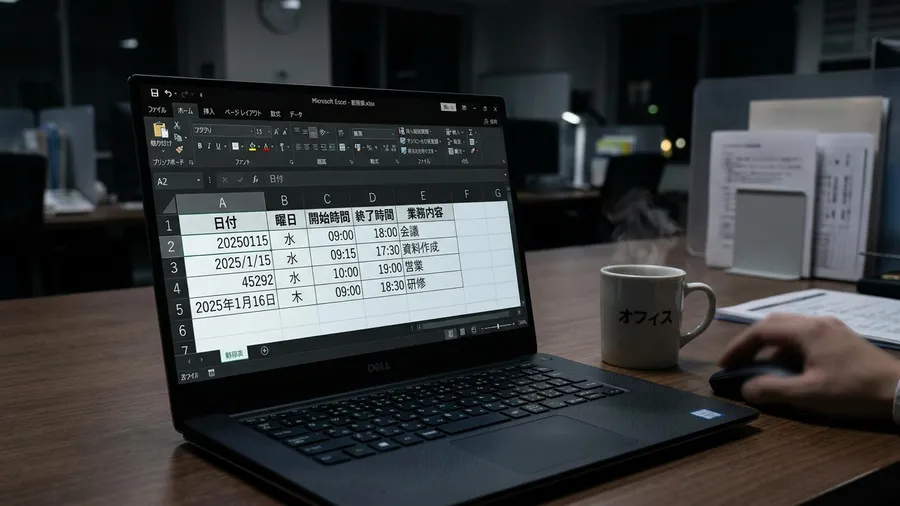
和暦と入力形式の多様性が招くデータ処理の壁
さらに追い打ちをかけるのが、和暦の存在でした。「令和7年1月15日」という日本独特の表記があります。見た目には分かりやすい表記と言えるでしょう。しかしプログラムにとっては非常に扱いにくいテキストデータです。これらの多様なフォーマットが入り混じったデータを読み込みます。pandasでは、日付列が「object型」となってしまいました。つまり単なる文字列として認識されてしまうのです。計算も並べ替えもできないこの状態をどうにかする必要があります。そうしない限り、自動化の道は開けないと痛感しました。
このような状況が生まれる背景には理由があります。部署ごとに異なる入力ルールが存在するからです。古いシステムの仕様が複雑に絡み合っていることも原因でしょう。現場に「形式を統一してください」とお願いしたこともありました。
ここで一度立ち止まって考えてみてください
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。現役エンジニアのサポートで、未経験から実践的なスキルを身につけられます。
日付変換 `pd.to_datetime`の落とし穴
pandasには魔法のように日付を変換してくれる関数があります。「pd.to_datetime()」という便利なものです。私は期待に胸を膨らませました。早速この関数を使って日付列を一括変換しようと試みます。最初は「format=’%Y%m%d’」と指定しました。8桁の数字をきれいに日付に変えることができたのです。その瞬間は「これでもう安心だ」と確信しました。しかし、現実はそう甘くはありません。処理が進むにつれて、突然画面が真っ赤なエラーで埋め尽くされます。
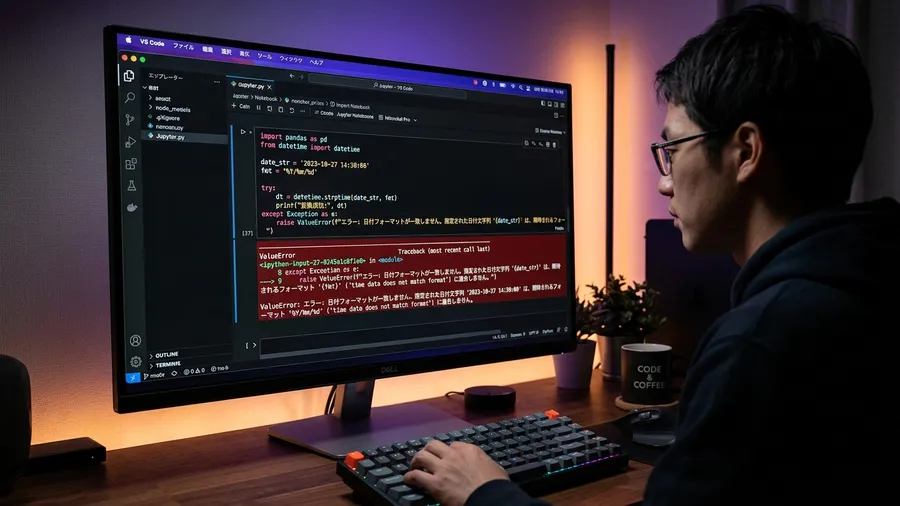
初めてpd.to_datetimeを使った時のことです。100行目までは完璧に変換できました。しかし101行目のスラッシュ区切りのデータに遭遇します。その瞬間にValueErrorで止まってしまいました。format指定を書き換えてはエラーが出る無限ループに陥ります。結局1時間以上も画面と睨めっこする羽目になりました。パズルのピースを無理やりはめ込もうとした気分です。箱を壊してしまったような徒労感に襲われました。
混在フォーマットによる処理停止
エラーの原因は明白でした。指定したフォーマットに合わない行が一つでもあると困ります。pandasはそこで処理を止めてしまいました。複数の形式が混在している列に対しての処理を考えます。一つの固定されたフォーマットを押し付けるのは無理がありました。エラーメッセージには冷酷な宣告が並んでいます。
Excelシリアル値変換の落とし穴
日付の変換作業の中で、最大の障壁となったものがあります。「45292」のような5桁の数字でした。これはいわゆるExcelのシリアル値です。一見すると単なる数値データにしか見えません。最初はシステムのバグで適当な数字が入ったのかと疑いました。しかし調べてみると、特殊な形式であることが分かったのです。Excelが日付を管理するための仕様でした。1900年1月1日を「1」としてカウントします。そこから何日が経過したかを示す整数値だったのです。
このシリアル値は、「20250115」といった数字とは異なります。全く性質が違うデータと言えるでしょう。そのため、文字列としての変換ルールを適用しようとします。すると全く見当違いの日付になってしまいました。pandasでこの数値を日付に戻すには特殊な手順が必要です。単位を「D(日)」に設定します。起点をExcelの仕様に合わせて「1899-12-30」にする必要がありました。この事実にたどり着くまで、私は何度も間違った日付を生成します。集計結果が合わないことに首を傾げていました。
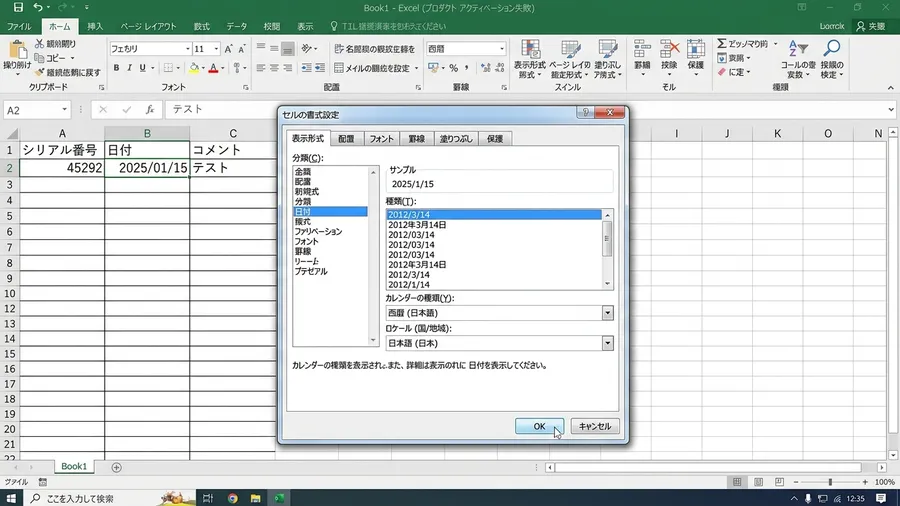
シリアル値が厄介なのは、見た目には普通の数字に見える点です。混在していることに非常に気づきにくいと言えます。
和暦データ変換の前処理、正規表現
和暦のデータに出会ったときのことです。私は正直なところ「勘弁してほしい」と思ってしまいました。「令和」「平成」といった元号が含まれる日付は大変です。pandasの標準的な変換機能だけでは太刀打ちできません。たとえ「format」を指定しようとしても困難です。日本語の漢字が含まれているだけで難易度が跳ね上がります。一つの列に複数の元号が混ざっている場合はさらに厄介でしょう。そのままpd.to_datetime()に渡すことは不可能な状態でした。
そこで私は、最終的な変換を行う前に一工夫入れます。日本語のテキストを西暦の形式に置換する「前処理」を行いました。Pythonの強力な機能である「正規表現」を使います。特定のパターンを抜き出し、計算によって西暦へ変換する関数です。例えば「令和」という文字を見つけたとしましょう。その後の数字に2018を足して西暦にするロジックを組み込みました。この地道な一歩手前の工夫が大切です。カオスなデータを整えるための鍵となりました。
正規表現とプログラミングの喜び
この前処理のコードを書いているときのことです。自分の仕事が少しだけ「プログラミング」に近づいた気がしました。単なるデータ入力から抜け出せたようでワクワクしたのです。最初は正規表現の書き方が分からず戸惑いました。記号が並ぶ不思議な文字列に苦戦します。しかし思い通りに和暦が西暦に書き換わった瞬間は格別でした。
自作関数で日付変換を制覇!エラー処理の妙
試行錯誤の末、私は変換用の関数を作成しました。「どんな形式が来ても動じない」頼もしい関数です。幸いなことに、pandasのバージョン2.0以降には新機能があります。引数に「format=’mixed’」というオプションが追加されました。これを使うと、スラッシュやハイフン区切りが混ざっていても安心です。pandasが自動的に推測して変換してくれます。しかし、それでも解決できない8桁数字やシリアル値が存在しました。和暦に対しては、私が作成した独自のロジックを適用します。順番に処理していく構成に仕上げました。
自作した変換関数を初めて全データに適用した時のことです。あれほど苦労していた数千行のデータが、一瞬で整った日付に変わりました。手作業で一文字ずつ修正していた時間が馬鹿らしく思えます。解放感を味わい、思わずデスクで小さくガッツポーズをしました。その日はいつもより一時間も早く仕事を終えることができました。夕食の味が格別に感じられたのを覚えています。
エラー無視で処理続行
このコードのポイントは、変換に失敗してもプログラムを止めないことです。「errors=’coerce’」を指定します。変換できなかった値を「NaT」という空の状態として残しました。そのまま次の処理へ繋げるようにしたのです。これにより、まずは変換しやすいものから順に片付けていきます。
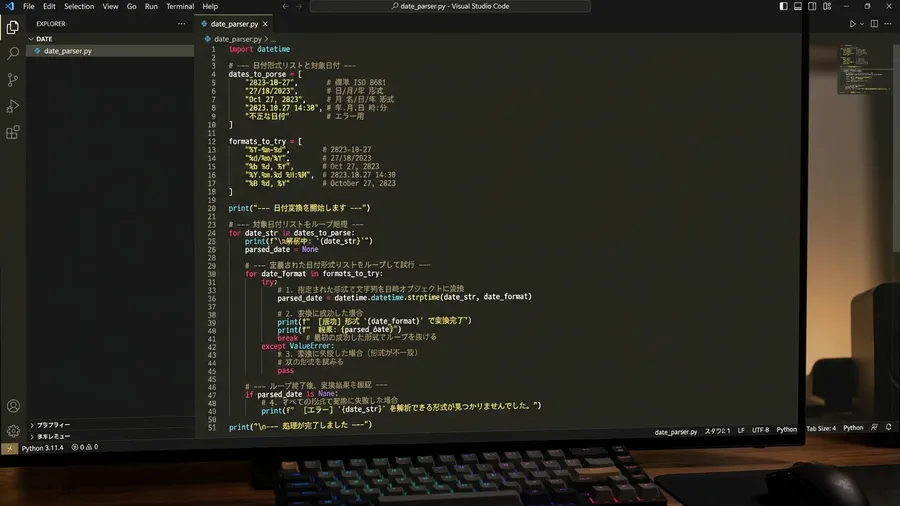
NaTで消えるデータ:私の失敗と対策
自動化が進む一方で、私は一つの恐怖を感じるようになりました。それは、「知らない間にデータが消えている」という事態です。「errors=’coerce’」を使うと、失敗した値は「NaT」に置き換わります。これはプログラムが止まらないという利点がありました。しかし裏を返せば、変換に失敗したことに気づかない危険性があります。そのまま集計を進めてしまう恐れがあるのです。変換後のデータを確認すると、末尾の行が全て空欄になっていました。そんな失敗を私は何度も経験したのです。
自動変換に成功したと大喜びで上司にレポートを提出しました。しかし後から詳しく見ると数件のデータが消えていたのです。変換できなかった行が静かにNaTに変わっていました。それが集計から漏れていたというわけです。慌てて修正しましたが、信頼を損ないかねないミスに冷や汗をかきました。それ以来、変換後には必ずNaTの数をカウントするコードを実行しています。
失敗を活かすNaT検知と原因特定
この失敗を教訓に、私は必ず確認ステップを入れるようにしました。変換処理の直後に「NaTがいくつ存在するか」を調べます。「df.isna().sum()」という一行のコードを追加しました。これだけで異常を一瞬で検知できるようになります。もしNaTが残っていれば、どの行のどんな値が原因だったのかを表示させます。その原因を特定してコードを修正しましょう。
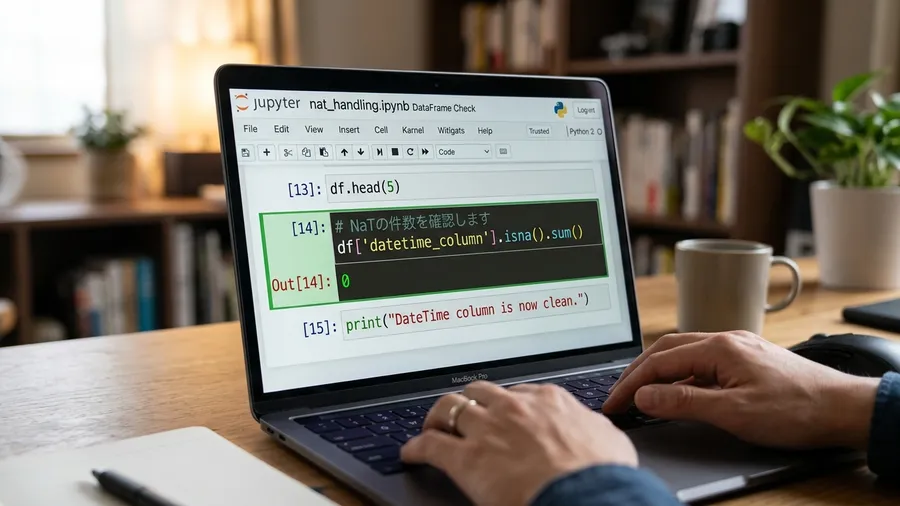
日付を甘く見ないデータ処理
Excelの画面上では同じ「日付」に見えていても、裏側には文字列・数値・シリアル値と全く異なる顔が存在します。今回学んだのは、見た目に騙されず正体を見極める大切さでした。pandasの「pd.to_datetime()」は強力ですが、複数フォーマットが混在する実務では一筋縄ではいきません。自分で「どんなフォーマットが来るか」を想定して手順を組み込む必要があると実感しました。
最初はエラーのたびに無力さを感じていましたが、今ではエラーこそ「データからのメッセージ」だと思えます。30分かかっていた作業が数秒で終わるようになりました。
もし手元にバラバラな日付データがあれば、まず一歩引いてその正体を観察してみてください。NaTを見逃さない仕組みさえあれば、失敗を恐れる必要はありません。少なくとも私は、この作業を通じて「日付を甘く見ない」という習慣が身につきました。同じ沼にはまっている方の参考になれば嬉しいです。
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
関連リンクとチェックリスト
関連記事
日付の変換エラーに悩んだ方は、yyyy/mm/ddとyyyy-mm-ddのような「似ているようで別物」な形式での失敗談もあわせて読むと、より深く理解できます。
関連書籍
Python業務自動化関連書籍を、手元で見返せる形にしておきたい場合
Pythonやデータ処理の自動化は、作りながら同じ基礎を何度も確認する場面が多いです。手元で見返せる本があると、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
PythonやExcel自動化スキルを持ったまま、ITエンジニアとして転職したい方には「EBAエデュケーション」が選択肢です。企業が求めるエンジニア像に合わせたカリキュラムで、実務直結のスキルを習得できます。
[アンケート] この記事は役に立ちましたか?