
複数のシステムからデータを引っ張り出して、一つにまとめる作業が定期的に回ってきます。やること自体は決まっていますし、何度もやっているのに、なぜかいつも途中で詰まります。出所が違うシステムが混ざると、データの形が全然揃っていないのです。
私が直面したのは、数千行に及ぶ社員名簿の突合業務でした。名前は同じはずなのに、なぜかVLOOKUP関数が「#N/A」を返し続けるのです。画面を睨みつけても、一見すると同じ漢字、同じ数字にしか見えません。この小さなズレが、私の貴重な残業時間をじわじわと削り取っていきました。
結局、原因は全角と半角の混在という、プログラミング以前の初歩的な問題でした。でも、これを手動で直していたら、何日あっても足りません。そこでPythonという道具を選びます。全角半角の壁を壊すことに決めたのです。この記事では私の経験した絶望を語ります。それをどう乗り越えたかも共有しましょう。
データ形式の不統一がもたらす重労働
社内には、導入時期もメーカーも異なるシステムがいくつも乱立しています。それぞれのシステムから出力されるCSVデータは、驚くほど個性的でした。基幹システムのデータは全て全角文字です。勤怠システムは半角カタカナが標準です。さらに、有志が作った管理表は全角と半角がランダムに混ざり合っていました。
各部署からExcelファイルを集めました。ファイルを統合しようとした時のことです。A列の氏名が「サトウ」と「サトウ」に分かれていました。手作業で置換しようと試みます。しかし変換漏れが怖くて目視で確認しました。3つのファイルを突合するだけで丸一日の消費です。本来やるべき分析作業には全く手が付けられません。
データの形がバラバラな状態です。これだけで名寄せの難易度が跳ね上がります。土台となるデータが汚れていると大変です。高度な関数を使っても意味をなしません。私は何度も突合を試みました。毎回データクレンジングの単純作業に引き戻されます。
データ不一致の無限ループ:白紙に戻る修正作業
当時、私が扱っていたのは3つのシステムからのデータで、項目数は合計15項目ほどありました。それぞれのシステムで同じ「氏名」「部署」「電話番号」のはずなのに、文字の形が揃っているものは一つもありませんでした。
この「白紙に戻る感覚」は、精神的に大きな負担となります。せっかく前進したと思っても安心できません。毎回不一致の原因探しから始まります。終わりが見えない作業の連続です。
全角半角の落とし穴
ある日の夕方、私は新しい名簿の突合に取り組んでいました。絶対に一致するはずのデータなのに、VLOOKUP関数が正常に動かないのです。数式は間違っていないし、参照範囲も正しいはずでした。セルの値をコピーして検索をかけます。それでもヒットしない怪現象に悩みました。
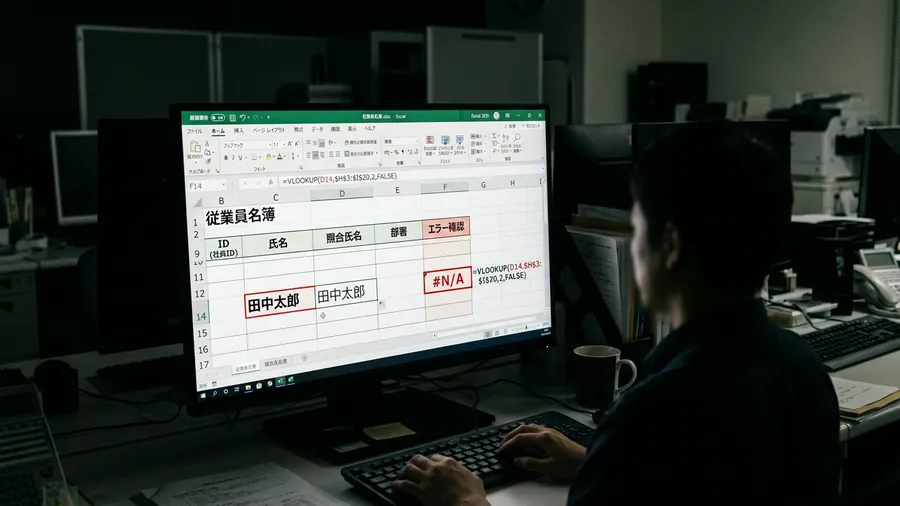
「何かがおかしい」と思いながら、数式バーを何度もクリックして確認しました。あることに気がつくのです。社員番号の「123」が、あるファイルでは全角の「123」になっていたのです。フォントの種類によっては、全角と半角の数字は見分けが困難になります。私はこの些細な違いを見つけるまでに、貴重な1時間を浪費してしまいました。
画面上で半角と全角の数字を交互にクリックします。カーソルの動きが違うことに気づきました。その瞬間は背筋が凍る思いです。正しいと信じたデータは砂上の楼閣でした。それから全てのセルを疑うようになります。作業スピードが極端に落ちてしまいました。
名寄せの壁、自動変換への道
たった1文字の違いで、コンピュータは「別人」だと判断します。人間にとっては同じ意味でも、システムにとっては全くの別物なのです。この厳格さが、名寄せ作業においては最大の敵となります。私は自分の目の頼りなさを知りました。人間の目視に頼った修正には限界があります。この時から、私はツールによる自動変換を真剣に模索し始めました。
ここで一度立ち止まって考えてみてください
Pythonや自動化スキルを体系的に習得して、ITエンジニアとしてのキャリアを切り開きたい方には「Enjoy Tech!(エンジョイテック)」が選択肢のひとつです。現役エンジニアのサポートで、未経験から実践的なスキルを身につけられます。
NFKC正規化で全角半角・記号を統一
Pythonで何とかならないかと調べていたら、「unicodedata」というモジュールにたどり着きました。NFKC正規化という処理を使うと、全角と半角をまとめて統一してくれるようです。正直、理屈はよくわかっていませんでしたが、とりあえず試してみました。
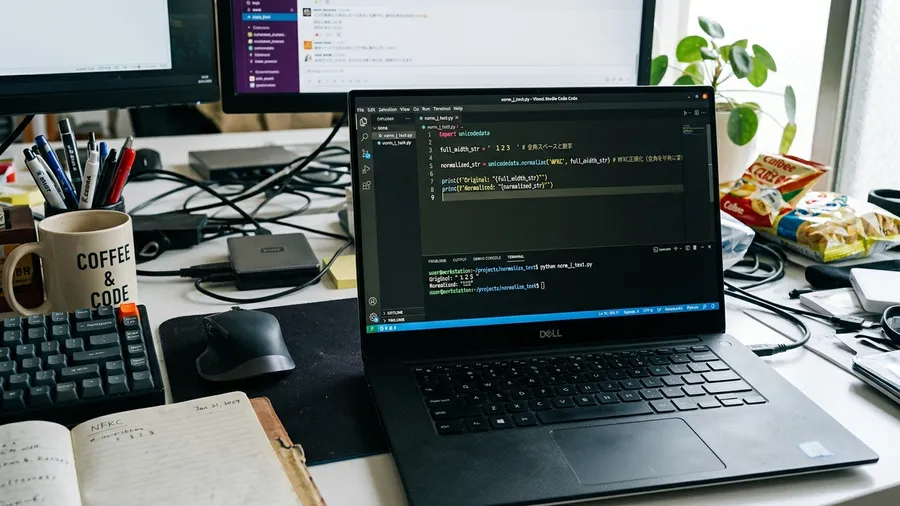
試しに、全角数字が混ざった電話番号のリストにこの処理をかけてみました。あんなに苦労していた全角の数字です。これが一瞬で半角に変換されて驚きました。ハイフンやカタカナの濁点なども、適切な形に整えられます。プログラムの実行によって数千行のデータが整列していくのです。その光景は快感でさえありました。
この正規化の素晴らしい点は、記号の揺れも同時に解決してくれることです。例えば、全角のプラス記号やカッコなども、標準的な半角記号に統一されます。これにより、電話番号の形式を整える前処理が劇的に楽になりました。これまで何度もExcelの置換機能を使ってきたのです。その必要はもうありません。
Pandasによる高速・簡単なデータ整形
処理速度も問題ありませんでした。1,000行のデータに対してNFKC正規化を実行しても、体感では一瞬で終わります。大量データでも十分実用的な速さでした。
Pandasを使えば、列全体に対して一括で正規化を適用することも可能です。短い命令を書くだけでデータは綺麗になります。「.str.normalize(‘NFKC’)」という記述を追加するだけです。
jaconvによる半角カタカナ全角化、名寄せとデータ連携
次なる課題は、氏名のふりがなに含まれる「半角カタカナ」でした。古いシステムのデータには特徴があります。高い確率で半角文字が混じっているのです。これを全角文字に揃えないと問題が起きます。五十音順の並べ替えがうまくいきません。

ここで活躍したのが「jaconv」という外部ライブラリでした。半角カタカナを全角に変換するツールです。濁点や半濁点も正しく結合してくれます。単純な置換では文字の結合が困難です。ツールを使えば完璧に処理できました。
ツールでふりがなを統一しました。今までマッチしなかったデータが一致します。500人分の情報がピタリと合いました。手作業の修正なら必ずミスが出たはずです。一瞬で全氏名が綺麗な全角カタカナに変わります。ようやく名寄せのスタートラインに立てました。
jaconv:データ変換の精度とシステム連携
氏名のデータは、一文字の間違いも許されません。特に人事データでは、名前の表記ミスは重大な失礼にあたります。jaconvによる自動変換は頼もしい機能です。ヒューマンエラーを防ぐための強力な盾となりました。ふりがなが揃うことで、VLOOKUPの照合率も飛躍的に向上します。データが整う喜びを、私はこの時初めて実感しました。
また、jaconvは逆に全角を半角にする処理も得意としています。システムの仕様に合わせて、自由自在に文字の種類を行き来できるようになりました。これにより、異なるシステム同士の連携も可能になります。
部署名英字統一による業務効率化
数字とカタカナをクリアしても、まだ厄介な問題が残っていました。それは部署名に含まれる「英字」の存在です。部署名にある英字の表記がバラバラでした。全角だったり小文字だったりするのです。これらは正規化だけでは完全に揃わない場合があり、個別の対策が必要でした。

`.upper()` で英字を大文字に揃えた後、さらにNFKC正規化をかけると、全角の英字も半角に統一されました。正直、この順番で組み合わせるだけで良かったのか、と拍子抜けするくらい簡単でした。ただ、知らなければ延々と手作業で直し続けていたと思います。
処理を加えた瞬間に変化が起きます。不一致リストが魔法のように消えていきました。部署名での名寄せが成功したのです。組織ごとの集計作業が自動化できます。これまで手動で合算していた時間が、一気にゼロになったのです。データの汚れを落とすことが、これほどまでに業務を軽くするとは思いませんでした。
部署名正規化で月次レポートの手作業ゼロへ
この部署名の統一処理を追加してから、月次レポートの集計で手作業が減りました。以前は部署ごとの合算で毎月3〜4時間かかっていた確認作業が、スクリプトを通した後はほぼゼロになりました。
特に外資系企業や、IT用語が頻出する部署名では、この半角全角問題が頻発します。この経験から大切なことを学びました。文字の正規化には3点セットが不可欠です。
残った数件の不一致は、もはや全角半角の問題ではなく、単純な入力ミスでした。
名寄せ自動化スクリプト:作業効率化と心の余裕
個別の変換処理がうまくいきました。私はこれらを一つのスクリプトにまとめます。CSVファイルの読み込み処理を組み込みました。文字変換などを実行するツールです。データを綺麗な状態で保存してくれます。これで、新しいデータが来るたびにコードを書き直す必要がなくなりました。
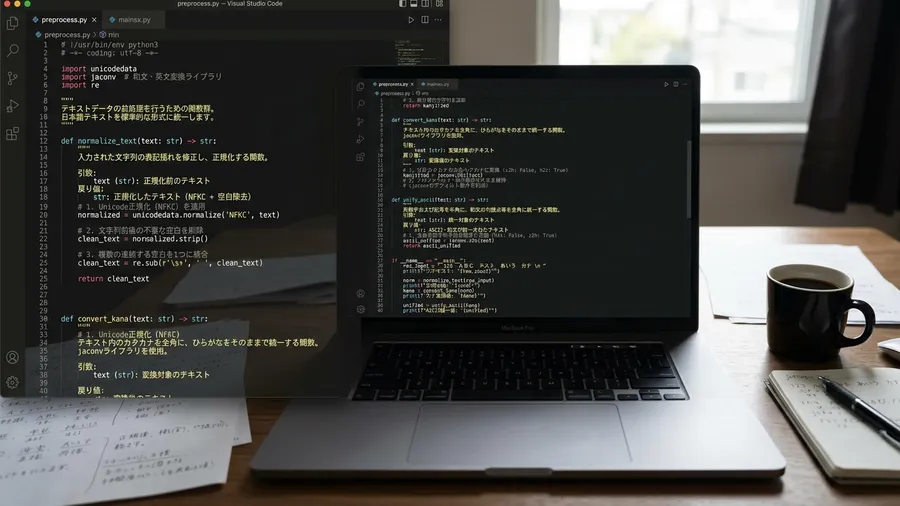
この自作ツールのおかげで、名寄せ作業のフローが劇的に変わりました。以前は目視のエラー探しからスタートです。今はまずスクリプトを通す作業から始まります。前処理が終わった時点で、データはすでに最高に綺麗な状態です。その後のExcel作業でエラーが出ることは、ほとんどなくなりました。
隣の席の同僚も不一致で悩んでいました。そこで自作のスクリプトを共有します。ボタン一つで直ったと驚く同僚の顔を見ました。自分の作ったものが他人の役に立つと知ります。この成功体験が自動化を進める原動力です。
名寄せ効率化がもたらす安心感
このスクリプトは、私にとっての大切な資産となりました。単なるコードの塊ではなく、私の苦労と試行錯誤が詰まった解決策です。一度作ってしまえば、何度でも使い回せます。名寄せは地味で辛い作業です。これを効率的でミスのないプロセスに変えられました。
ツール化の恩恵は、作業時間の短縮だけではありません。「いつでも確実に直せる」という安心感が、心の余裕を生みました。急なデータ提出を求められても、もう慌てることはありません。
名寄せスクリプト、今も現役 数万件データチェック、…
あれから数年が経ち、会社では新しいシステムへの移行が何度か行われました。そのたびにデータの書き出しと取り込みが発生します。あの地獄の名寄せが必要です。しかし、私にはあの時作ったPythonスクリプトがあります。今でも現役で、私の業務を支えてくれる存在です。
システムが新しくなっても人間が入力します。文字の揺れは完全には無くなりません。新旧のデータが混ざる移行期こそ大変です。このスクリプトの真価が発揮されます。PCの中には過去の自分が残した知恵が存在するのです。いつでも動ける状態で待機しています。
大規模なシステム刷新プロジェクトに参加しました。数万件の移行データチェックを任されます。他のメンバーはExcelで悪戦苦闘していました。私はスクリプトを数分回すだけで完了させます。上司から仕事が早いと褒められました。過去の苦労が支えてくれているだけと思い苦笑いです。
全角半角の悩みをPythonで解決
全角半角の問題は、一見すると小さな悩みかもしれません。しかし、それが積もり積もって、現場の人間を疲弊させています。
Excelの画面を睨みつけている方がいるかもしれません。全角と半角の違いに絶望していませんか。ぜひPythonを試してみてください。unicodedataやjaconvは、あなたの強力な味方になってくれます。一度その便利さを知れば、もう二度と手作業での置換には戻れなくなるはずです。
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
完全版のご案内
全角半角バラバラのデータを名寄せするPython前処理コード(コピペ完全版)
氏名・部署・電話番号の表記ゆらぎをまとめて整える前処理コードの完全版は、noteで公開しています。自分が実際に失敗した3ケースの回避方法まで含めてありますので、同じ名寄せ作業で詰まっている方は参考にしてみてください。
関連リンクとチェックリスト
関連記事
全角半角の前処理が終わったら、次は日付フォーマットの混在でまた詰まることがあります。同じ「システムごとにデータ形式が違う」問題を日付の側面から書いた記事です。
関連書籍
Python業務自動化関連書籍を、手元で見返せる形にしておきたい場合
Pythonやデータ処理の自動化は、作りながら同じ基礎を何度も確認する場面が多いです。手元で見返せる本があると、調べ直しの時間を減らしやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
PythonやExcel自動化スキルを持ったまま、ITエンジニアとして転職したい方には「EBAエデュケーション」が選択肢です。企業が求めるエンジニア像に合わせたカリキュラムで、実務直結のスキルを習得できます。
[アンケート] この記事は役に立ちましたか?