
月末の午後、経理や総務の担当者にとって最も神経を使う時間がやってきます。
集計レポートの提出期限が迫ります。
ようやく数字がまとまった瞬間の安堵感は何物にも代えがたいものです。
しかし、その安堵が一瞬にして凍りつくような出来事が私の身に起きました。
自信を持って提出したはずの部署別集計レポートです。
それは実は見るも無残な状態でした。
上司から指摘されるまで、私は全く気づきません。
その「静かな崩壊」は密かに進行していました。
原因はシステムのバグでも計算式のミスでもありません。
あまりにも日常的で些細な一文字の差にありました。
この記事では、私が実際に体験した集計トラブルをお話しします。
部署名の表記揺れが引き起こした問題でした。
それをどう乗り越えたかについても共有いたします。
Excelの便利な機能が、時には牙を剥くこともあります。
その仕組みを理解し、再発を防ぐ知恵をお伝えできれば幸いです。
背筋が凍る集計ミス
月末17時という、定時退社を意識し始めるタイミングでした。
作成したばかりの集計レポートを上司のデスクへ持っていきます。
その時は、ミスがあるなんて微塵も思っていなかったのです。
しかし、レポートを受け取った上司の表情が変わりました。
見る間に曇っていくのが分かったのです。
「これ、部署がバラバラになっていないか」という声が響きました。
私は慌てて手元の資料を覗き込みます。
本来、我が社の部署別集計は4行で完結するはずです。
営業一課から四課までのデータとなります。
ところが、提出したピボットテーブルの表には違いがありました。
なぜか8行ものデータが並んでいたのです。
月末17時に集計レポートを提出し、直後に上司から指摘を受けました。
部署別集計ミス、冷や汗の瞬間
よく見ると、同じはずの「営業一課」が2つの行に分かれています。
しかも、それぞれの行に別々の数字が割り振られていました。
合計金額は合っているようです。
実は部署ごとに集計が割れているという最悪の状態でした。
背筋に冷たいものが走る感覚を、今でも鮮明に覚えています。提出直前に「合計が合わない」と気づいたときの、あの焦りは忘れられません。
自分では何度も確認したつもりでした。
しかし一瞬の油断が大きなミスを招いてしまったのです。
オフィスの時計が刻む音が、いつもより大きく聞こえました。
集計データ分裂の原因究明
上司に謝罪し、私は脱兎のごとく自分のデスクに戻りました。
パソコンの画面を開き、先ほど保存したファイルをクリックします。
心臓の鼓動が耳元まで聞こえてくるような嫌な緊張感に包まれたことがあります。上司への報告資料を作るたびに「今月は大丈夫か」と確認し直すのが習慣になってしまっていました。
修正しなければならないという焦りが、思考を支配していきます。
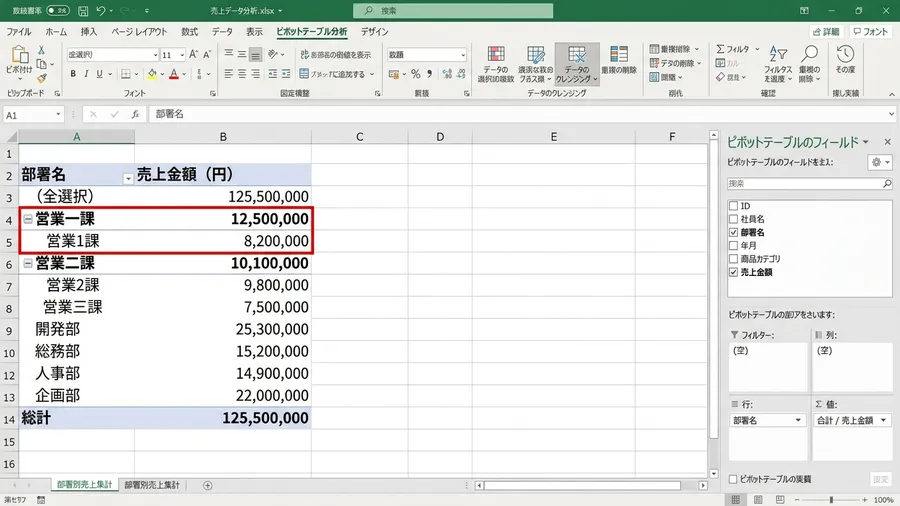
本来4行のはずの部署別集計が、8行に分裂してしまいました。「営業一課」と「営業1課」がそれぞれ別集計として計上されていたのです。
4つの部署がそれぞれ2行に分かれてしまったのです。
ピボットテーブル部署名分裂、焦る原因究明
ピボットテーブルを再更新しても、状況は変わりません。
営業一課から四課まで、すべての部署が綺麗に二つずつに分裂していました。
私は、各セルの値を一つずつ目で追い始めます。
パッと見ただけでは、どの行も正しい部署名が入っているように見えました。
しかし、ピボットテーブルが別々の行として認識しています。
そこには必ず何らかの違いがあるはずです。
私はフィルター機能を使いました。
データの元となっている明細シートを確認するためです。
一分一秒が惜しい状況で、マウスを持つ手が少し震えていました。
焦れば焦るほど、単純な作業も時間がかかってしまうものです。
VBA・Pythonをもっと本格的に学ぶなら
VBAやPythonを実務レベルまで引き上げたい方には「侍エンジニア」がおすすめです。マンツーマン指導・オーダーメイドカリキュラムで、文系出身でも挫折しにくい環境が整っています。無料カウンセリングだけでも学習ロードマップが明確になります。
たった1文字。集計を分けた表記揺れ
明細データをじっくり観察して、ようやく原因が判明しました。
一つ目の「営業一課」は、漢字の「一」を使っていました。
そして、もう一方の「営業1課」は、算用数字の「1」だったのです。
画面上では全く同じ部署を指しているつもりでした。
しかし、たった1文字の表記の違いで集計が割れてしまったのです。
この混在を見つけたとき、あまりの些細な原因に眩暈がしました。何時間も悩んでいた原因が、全角と半角の違いだったとわかったときの脱力感は、今も忘れられません。
自分では完璧にチェックしたつもりでした。
人間の目はなんて頼りないのだろうと痛感した瞬間です。
Excel集計、一文字違いの誤集計
Excelの集計機能は、一文字でも違えば「全く別のもの」として扱います。
人間なら文脈で容易に判断できます。
しかしコンピュータにその融通は利きません。
漢数字の「一」と、算用数字の「1」の違いです。
見た目は似ていても、データとしては完全に別物なのです。
この表記のゆれによって、数字が分散してしまいました。
本来合算されるべき数字がそれぞれの行に分かれたのです。
4つの部署すべてでこの現象が起きていました。
合計8行という奇妙なレポートが出来上がってしまったのです。データを提出した後で気づいたため、訂正の連絡を入れる羽目になりました。
たった一文字の違いが、これほどまでに大きな結果の差を生みます。
文字コードの罠:Excel集計エラー
表記ゆれの原因は、漢数字と算用数字だけではありませんでした。
さらに詳しく調べると、全角と半角の混在も見つかります。
挿入されている不要なスペースもありました。
「営業一課」の後に、目に見えない全角スペースが入っていたのです。
Excelにとってスペースの有無は大きな問題です。
「営業一課」と「営業一課 」は異なる文字列として認識されます。
全角の「1」と半角の「1」についても同じことが言えるでしょう。
コンピュータの内部では異なる文字コードとして処理されます。
これらが静かに、しかし確実に集計結果を破壊していました。
COUNTIF関数やSUMIF関数を使っている場合も同様のトラブルが起きます。
指定した条件と一文字でも不一致があれば、計算対象から外れるのです。
目視では同じに見えるのに、計算結果が全く合いません。
この「文字コードの罠」は、Excel作業で最も厄介な敵の一つと言えるでしょう。
私たちは普段、文字を「意味」で捉えています。
しかしExcelはそれらを「符号」として認識しています。
その根本的な認識のギャップが、集計作業を困難にする原因でした。
この問題は、一度発生すると原因の特定に非常に時間がかかります。
多様な入力経路と表記揺れ、不整合の根本原因
なぜ、これほどまでにバラバラなデータが集まってしまったのでしょうか。
私は、元データの入手経路を一つずつ遡ってみることにしました。
すると、複数のルートからデータが集約されている実態が浮かび上がります。
一部のデータは、営業部が共有フォルダに入力したファイルでした。
そこから直接コピペして利用していたものです。
また、別のデータは社内の基幹システムからCSV形式で出力されました。
さらに別の課からは、メールに添付されたフォーム形式のExcelが届きます。
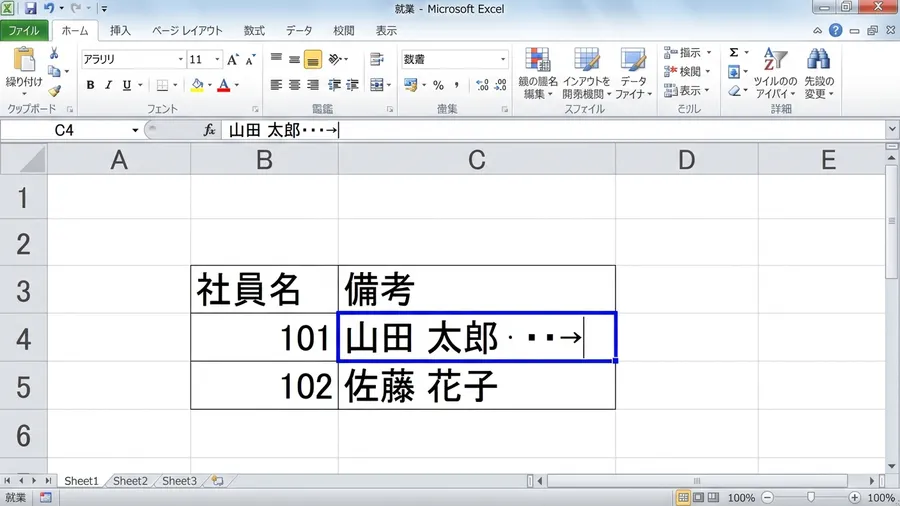
原因特定に約1時間かかりました。表記の揺れが原因だとわかってからも、手作業でSUBSTITUTE関数を重ねる修正に30分以上費やしました。
さらにSUBSTITUTE関数の応急処置に約30分を要したのです。
入力する人によって、様々な癖がありました。
漢数字を使ったり、数字は半角と決めていたりします。
無意識にスペースを入れてしまう人もいました。
多様な入力と個別管理が招くデータ不整合
複数のシステムや手入力が混在する環境は危険です。
こうした表記の多様性が「増殖」しやすい構造になっていたのです。
誰かが悪意を持って間違えたわけではありません。
入口が整っていないことが根本的な問題でした。
各部署が良かれと思って個別に管理していたデータの欠片が集まります。
その結果、大きな不整合が生じていたのです。
自由入力の罠
自由度の高い入力環境の危うさを痛感しました。
明確な入力ルールが共有されていない現場は多く存在します。
そのような場所では、個人の習慣がそのままデータに反映されるのです。
特に、部署名のような「誰でも分かるはずの言葉」は要注意でしょう。
入力時の注意が疎かになりがちだからです。

「営業一課」と入力しても、「営業1課」と入力しても同じ意味に思えます。
社内ではどちらも正解として通用してしまうでしょう。
しかし、それを集計の材料として使う側にとっては致命的な毒になります。
自由に入力できるということは、とても危険な状態と言えるでしょう。
「間違いの選択肢」を入力者に与えているのと同じだからです。
入力経路が増えれば増えるほど、表記ゆれを制御するのは困難になります。
一人一人の善意に頼る運用では限界がありました。
いつか必ず今回のような集計ミスが再発してしまうでしょう。
データを受け取る側の工夫だけでは不十分です。
データの入り口を絞る設計の重要性を改めて感じました。
現場の使い勝手と、データの整合性をいかに両立させるか。
その難問に対する答えを持っていないまま作業を続けていました。
それが私の最大の反省点です。
月末のSUBSTITUTE悪夢、部署名統一
原因は分かりましたが、今は一刻を争う月末の夕方です。
私は、ExcelのSUBSTITUTE関数を使いました。
全データの部署名を急いで正規化することにしたのです。
まず、漢数字の「一」から「四」を置換します。
すべて算用数字の「1」から「4」に変える数式を作成しました。
SUBSTITUTE関数を何層にもネストして、不格好な長い数式を作りました。
一文字ずつ置換対象を増やしていく作業は、パズルを解くようです。
失敗すればまた集計が割れるという恐怖で心臓がバクバクしました。
関数を入力し終え、ピボットテーブルがスッと4行にまとまります。
その瞬間、ようやく大きなため息が出ました。
さらに、TRIM関数を組み合わせて前後の不要なスペースを削除します。
そしてASC関数で全角英数字を半角に統一しました。
SUBSTITUTE(A1,”一”,”1″)
疲労困憊の応急処置レポート
このような処理を繰り返し、なんとか部署名を統一させます。
その状態でピボットテーブルを作成し直しました。
急いで新しいレポートを印刷し、上司の元へ走り込みます。
時計の針は18時を回ろうとしていました。
作業を終えた後の疲労感は尋常ではありません。
「もう二度とやりたくない」という思いが勝っていたのです。
応急処置の限界を感じつつも、まずはその場を乗り切るしかありませんでした。
一時しのぎの限界と根本改善への決意
なんとか当日のレポート提出は間に合いましたが、心の中は晴れません。
今回使ったSUBSTITUTE関数のネストは、応急処置に過ぎないからです。
来月の月末になれば、また新しいデータが送られてきます。
そこに表記ゆれが混じっていることは目に見えていました。
「また来月もこの不格好な関数を組み直すのか」と考えます。
そう思うと、ひどく暗い気持ちになりました。
しかも、今回は営業一課から四課までで済みました。
しかし今後、新しい部署ができたり名称が変わったりするかもしれません。
そのたびに関数を修正しなければならないのです。
手作業での置換や、複雑なExcel関数による対応には限界があります。
人間が手作業を加える工程が残っている限り安心できません。
そこが新たなミスの温床になる可能性も否定できないからです。
本当の意味で「直った」と言えるためには工夫が求められます。
属人的な対処法を捨て、機械的に処理できる仕組みを作らなければなりません。
私はそのように確信しました。
今回の件で、自分の作業スタイルを根本から見直す決意を固めます。
同じ苦労を繰り返さないための対策です。
もっとスマートな方法を探さなければならないと強く感じました。
Pythonでデータクリーン化、月末作業の劇的改善
翌月から、私は集計作業にPythonを取り入れることにしました。
これまで手作業や複雑な関数で行っていた処理を変えるためです。
データの取込とクレンジングを、プログラムで自動化します。
Pandasというライブラリを使えば、驚くほど簡単でした。
表記ゆれの修正は非常にシンプルに書けたのです。
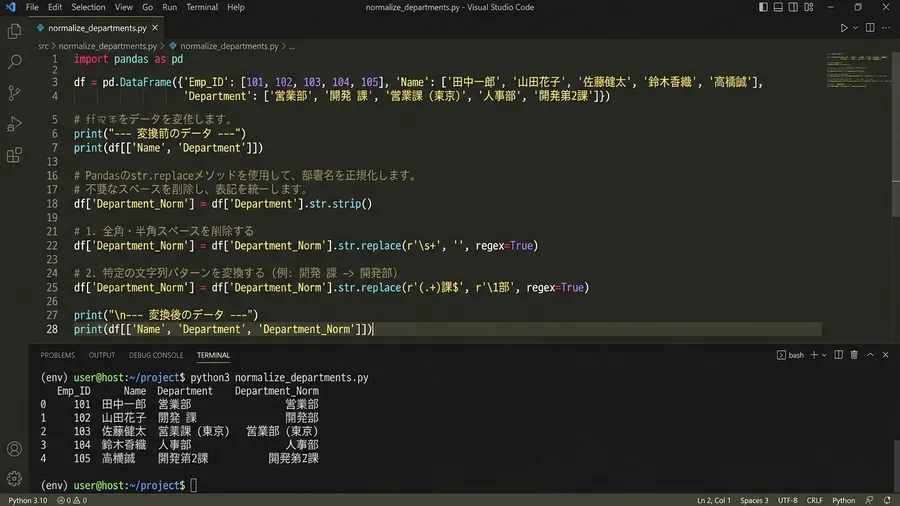
df[“部署名”] = df[“部署名”].str.replace(“一”, “1”).str.strip()
翌月からPythonの取込処理にstr.replaceの1行を追加し、再発はゼロになりました。あれほど悩まされていた問題が、たった1行で解決できたことに、自分でも驚きました。
この一行を追加するだけで、取込時に自動で変換を行ってくれます。
漢数字が算用数字に置換され、不要なスペースも削除されました。
全角半角の統一も一瞬で終わります。
一度コードを書いてしまえば、来月以降も同じボタンを押すだけです。
完璧にクリーンなデータが準備できるようになりました。
Pythonで月末業務が激変
Pythonを導入してから初めての月末を迎えます。
ボタン一つでデータが綺麗に揃ったのを見た時は感動しました。
以前はあんなに苦労して関数を書いていたのが嘘のようです。
プログラムが私の代わりに、正確にデータを整えてくれます。
その安心感のおかげで、月末のストレスが劇的に軽減されました。
データ入口の正規化と自動処理
今回の経験を通じて学んだのは、データの入口の重要性です。
集計の信頼性はそこで決まるという事実でした。
どんなに高度な分析手法を使っても、元のデータが汚れていれば無意味です。
結果は決して信用できません。
表記ゆれは単なる入力ミスではありません。
システム設計上の課題として捉えるべきものでした。
もちろん、すべての入力フォームに制限をかけるのが理想です。
自由な入力を禁止できれば一番良いでしょう。
しかし、現実の業務ではどうしても複数の経路が存在します。
そこからバラバラな形式のデータが集まってくるのです。
その現実を受け入れた上で、新たな対策を講じなければなりません。
いかに早い段階で「正規化」するかが、集計担当者の腕の見せ所なのです。
Python自動化で表記ゆれ解消と時間創出
Pythonを使った自動処理は、そのための強力な武器になりました。
人間が気をつけるのではなく、仕組みがデータを守ります。
この考え方にシフトしてから、月末に冷や汗をかくことはなくなりました。
以前はデータの修正に数時間を費やしていました。
今ではその時間をより創造的な作業に充てることができています。
もし、あなたが今、Excelの集計が合わずに悩んでいるとします。
まずは部署名の一文字一文字を疑ってみてください。
そこには、静かに集計を壊す小さな表記ゆれが隠れているかもしれません。
それを一つずつ手で直すのはやめましょう。
無料プレゼント
Excel業務を自動化する前に確認するチェックリスト(PDF)
自動化していい作業かどうか、VBAかPythonか、最初に避けるべき落とし穴。実務でよく迷うポイントを1枚にまとめました。メールアドレスだけで受け取れます。
¥980 ミニキット
コピペで動かせる3スクリプト+自動化チェックリスト
最新ファイルの自動選択・部署名ゆれの正規化・CSV文字コード確認の3本セット。今週の作業を1つだけ楽にするための最小キットです。
関連リンクとチェックリスト
■ 著者はこうして解決の糸口を見つけた
データの揺れや名寄せ問題に悩んだ著者が、Pythonで根本対処にたどり着くまでの道のりもあわせてどうぞ。
関連書籍
Excel・VBA関連書籍を、手元で見返せる形にしておきたい場合
ExcelやVBAのトラブルは、基本の考え方をあとから見返せるだけでかなり楽になります。手元に1冊置いておくと、同じエラーで止まったときに確認しやすいです。
学習サービスとアンケート
このスキルを活かしてさらに前へ進むなら
PythonやExcel自動化スキルを持ったまま、ITエンジニアとして転職したい方には「EBAエデュケーション」が選択肢です。企業が求めるエンジニア像に合わせたカリキュラムで、実務直結のスキルを習得できます。
[アンケート] この記事は役に立ちましたか?